Class that stores all relevant simulation state data with methods for time stepping. More...
#include <REMORA.H>
Public Member Functions | |
| REMORA () | |
| REMORA (const amrex::RealBox &rb, int max_level_in, const amrex::Vector< int > &n_cell_in, int coord, const amrex::Vector< amrex::IntVect > &ref_ratio, const amrex::Array< int, AMREX_SPACEDIM > &is_per, std::string prefix) | |
| virtual | ~REMORA () |
| void | Evolve () |
| Advance solution to final time. | |
| void | WriteAtFinalTime () |
| Write checkpoint and plotfiles at end of simulation. | |
| void | WriteAtIntermediateTime (int step, amrex::Real cur_time) |
| Write checkpoint and plotfiles at intermediate point of simulation, if needed. | |
| virtual void | ErrorEst (int lev, amrex::TagBoxArray &tags, amrex::Real time, int ngrow) override |
| Tag cells for refinement. | |
| void | InitData () |
| Initialize multilevel data. | |
| amrex::Real | EvolveOneStep (amrex::Real time, amrex::Real dt_request) |
| void | init_only (int lev, amrex::Real time) |
| Init (NOT restart or regrid) | |
| void | restart () |
| void | post_timestep (int nstep, amrex::Real time, amrex::Real dt_lev) |
| Called after every level 0 timestep. | |
| void | PackSurfaceState (amrex::Vector< amrex::MultiFab * > &state, amrex::Real time) |
| Extracts SST from the 3D conservative state for the atmospheric driver. | |
| void | ApplyAtmosphericStates (const amrex::Vector< amrex::MultiFab * > &states, amrex::Real time) |
| Receives atmospheric states from the driver and applies unit conversions. | |
| void | sum_integrated_quantities (amrex::Real time) |
| Integrate conserved quantities for diagnostics. | |
| amrex::Real | volWgtSumMF (int lev, const amrex::MultiFab &mf, int comp, bool local, bool finemask) |
| Perform the volume-weighted sum. | |
| bool | is_it_time_for_action (int nstep, amrex::Real time, amrex::Real dt, int action_interval, amrex::Real action_per) |
| Decide if it is time to take an action. | |
| virtual void | MakeNewLevelFromCoarse (int lev, amrex::Real time, const amrex::BoxArray &ba, const amrex::DistributionMapping &dm) override |
| Make a new level using provided BoxArray and DistributionMapping and fill with interpolated coarse level data. Overrides the pure virtual function in AmrCore. | |
| virtual void | RemakeLevel (int lev, amrex::Real time, const amrex::BoxArray &ba, const amrex::DistributionMapping &dm) override |
| Remake an existing level using provided BoxArray and DistributionMapping and fill with existing fine and coarse data. Overrides the pure virtual function in AmrCore. | |
| virtual void | ClearLevel (int lev) override |
| Delete level data Overrides the pure virtual function in AmrCore. | |
| virtual void | MakeNewLevelFromScratch (int lev, amrex::Real time, const amrex::BoxArray &ba, const amrex::DistributionMapping &dm) override |
| Make a new level from scratch using provided BoxArray and DistributionMapping. Only used during initialization. Overrides the pure virtual function in AmrCore. | |
| void | set_grid_scale (int lev) |
| Set pm and pn arrays and x/y coords on level lev. | |
| void | set_grid_coords_from_grid_scale (int lev) |
| Set x/y coords on level lev based on pm and pn. | |
| void | set_curvilinear_terms_from_grid_scale (int lev) |
| Set curvilinear derivative terms on level lev based on pm and pn. | |
| void | set_grid_vars_averaged_down (int lev) |
| Set pm/pn by averaging down from higher-resolution grid. | |
| void | set_zeta_to_Ztavg (int lev) |
| Set zeta components to be equal to time-averaged Zt_avg1. | |
| void | calculate_nodal_masks (int lev) |
| Calculate u-, v-, and psi-point masks based on rho-point masks after analytic initialization. | |
| void | fill_3d_masks (int lev) |
| Copy maskr to all z levels. | |
| void | update_mskp (int lev) |
| Set psi-point mask to be consistent with rho-point mask. | |
| amrex::Real | estTimeStep (int lev) const |
| compute dt from CFL considerations | |
| void | remora_advance (int level, amrex::MultiFab &cons_old, amrex::MultiFab &cons_new, amrex::MultiFab &xvel_old, amrex::MultiFab &yvel_old, amrex::MultiFab &zvel_old, amrex::MultiFab &xvel_new, amrex::MultiFab &yvel_new, amrex::MultiFab &zvel_new, amrex::MultiFab &source, const amrex::Geometry fine_geom, const amrex::Real dt, const amrex::Real time) |
| Interface for advancing the data at one level by one "slow" timestep. | |
| amrex::MultiFab & | build_fine_mask (int lev) |
| Make mask to zero out covered cells (for mesh refinement) | |
| void | WritePlotFile (int istep) |
| main driver for writing AMReX plotfiles | |
| void | WriteMultiLevelPlotfileWithBathymetry (const std::string &plotfilename, int nlevels, const amrex::Vector< const amrex::MultiFab * > &mf, const amrex::Vector< const amrex::MultiFab * > &mf_nd, const amrex::Vector< const amrex::MultiFab * > &mf_u, const amrex::Vector< const amrex::MultiFab * > &mf_v, const amrex::Vector< const amrex::MultiFab * > &mf_w, const amrex::Vector< const amrex::MultiFab * > &mf_2d_rho, const amrex::Vector< const amrex::MultiFab * > &mf_2d_u, const amrex::Vector< const amrex::MultiFab * > &mf_2d_v, const amrex::Vector< std::string > &varnames_3d, const amrex::Vector< std::string > &varnames_2d_rho, const amrex::Vector< std::string > &varnames_2d_u, const amrex::Vector< std::string > &varnames_2d_v, const amrex::Vector< amrex::Geometry > &my_geom, amrex::Real time, const amrex::Vector< int > &level_steps, const amrex::Vector< amrex::IntVect > &rr, const std::string &versionName="HyperCLaw-V1.1", const std::string &levelPrefix="Level_", const std::string &mfPrefix="Cell", const amrex::Vector< std::string > &extra_dirs=amrex::Vector< std::string >()) const |
| write out particular data to an AMReX plotfile | |
| void | WriteGenericPlotfileHeaderWithBathymetry (std::ostream &HeaderFile, int nlevels, const amrex::Vector< amrex::BoxArray > &bArray, const amrex::Vector< std::string > &varnames_3d, const amrex::Vector< std::string > &varnames_2d_rho, const amrex::Vector< std::string > &varnames_2d_u, const amrex::Vector< std::string > &varnames_2d_v, const amrex::Vector< amrex::Geometry > &my_geom, amrex::Real time, const amrex::Vector< int > &level_steps, const amrex::Vector< amrex::IntVect > &rr, const std::string &versionName, const std::string &levelPrefix, const std::string &mfPrefix) const |
| write out header data for an AMReX plotfile | |
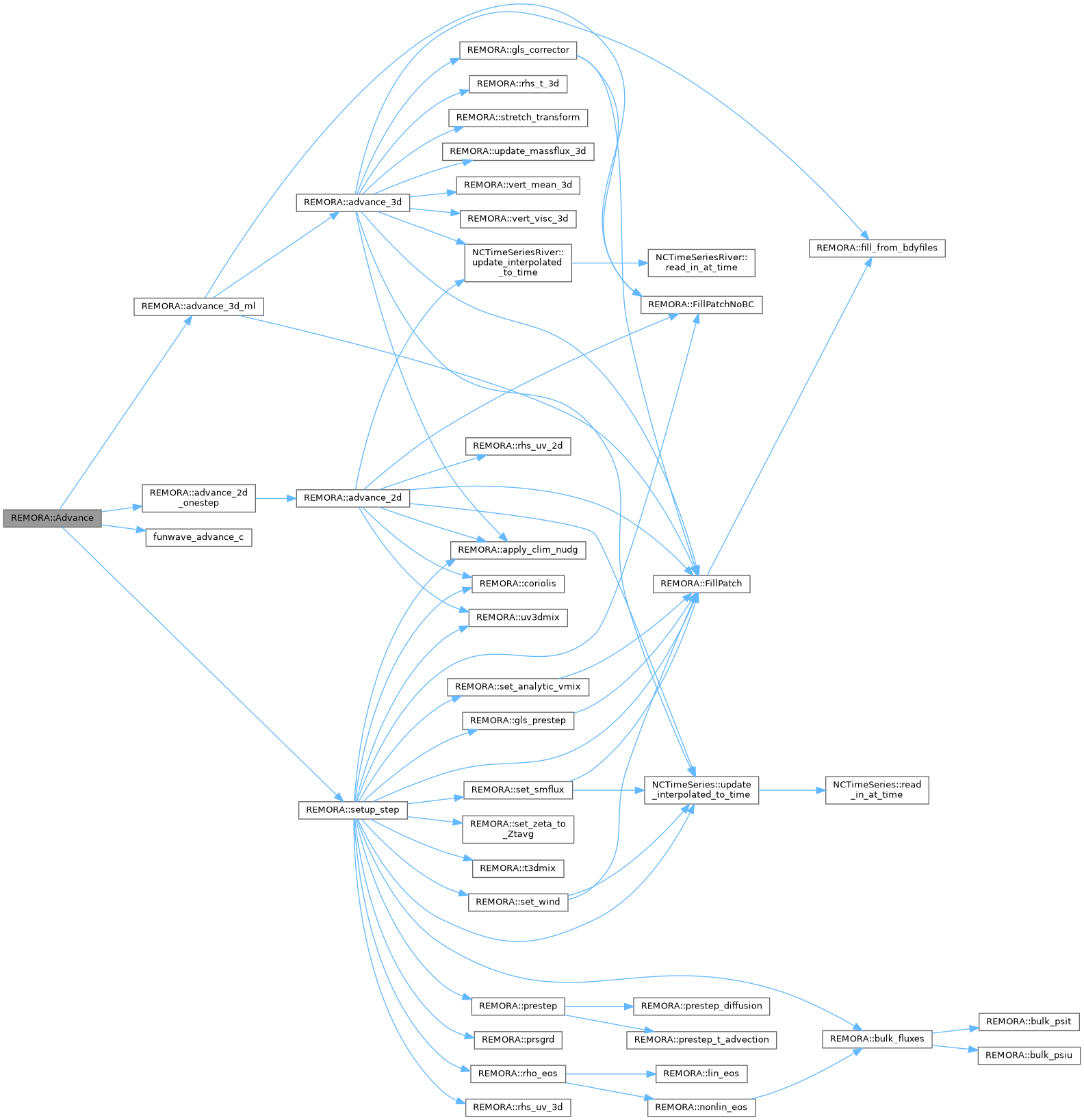
| void | Advance (int lev, amrex::Real time, amrex::Real dt_lev, int iteration, int ncycle) |
| advance a single level for a single time step | |
| void | setup_step (int lev, amrex::Real time, amrex::Real dt_lev) |
| Set everything up for a step on a level. | |
| void | advance_3d_ml (int lev, amrex::Real dt_lev) |
| 3D advance on a single level | |
| void | advance_2d_onestep (int lev, amrex::Real dt_lev, amrex::Real dtfast_lev, int my_iif, int nfast_counter) |
| 2D advance, one predictor/corrector step | |
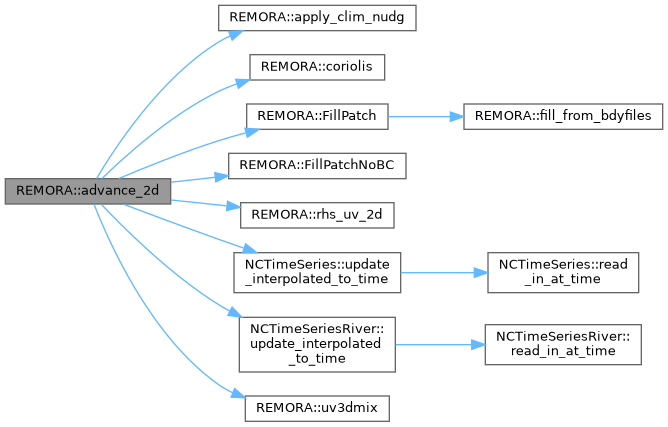
| void | advance_2d (int lev, amrex::MultiFab const *mf_rhoS, amrex::MultiFab const *mf_rhoA, amrex::MultiFab *mf_ru2d, amrex::MultiFab *mf_rv2d, amrex::MultiFab *mf_rufrc, amrex::MultiFab *mf_rvfrc, amrex::MultiFab *mf_Zt_avg1, std::unique_ptr< amrex::MultiFab > &mf_DU_avg1, std::unique_ptr< amrex::MultiFab > &mf_DU_avg2, std::unique_ptr< amrex::MultiFab > &mf_DV_avg1, std::unique_ptr< amrex::MultiFab > &mf_DV_avg2, std::unique_ptr< amrex::MultiFab > &mf_rubar, std::unique_ptr< amrex::MultiFab > &mf_rvbar, std::unique_ptr< amrex::MultiFab > &mf_rzeta, std::unique_ptr< amrex::MultiFab > &mf_ubar, std::unique_ptr< amrex::MultiFab > &mf_vbar, amrex::MultiFab *mf_zeta, amrex::MultiFab const *mf_h, amrex::MultiFab const *mf_pm, amrex::MultiFab const *mf_pn, amrex::MultiFab const *mf_fcor, amrex::MultiFab const *mf_visc2_p, amrex::MultiFab const *mf_visc2_r, amrex::MultiFab const *mf_mskr, amrex::MultiFab const *mf_msku, amrex::MultiFab const *mf_mskv, amrex::MultiFab const *mf_mskp, amrex::Real dtfast_lev, bool predictor_2d_step, bool first_2d_step, int my_iif, int &next_indx1) |
| Perform a 2D predictor (predictor_2d_step=True) or corrector (predictor_2d_step=False) step. | |
| void | advance_3d (int lev, amrex::MultiFab &mf_cons, amrex::MultiFab &mf_u, amrex::MultiFab &mf_v, amrex::MultiFab *mf_sstore, amrex::MultiFab *mf_ru, amrex::MultiFab *mf_rv, std::unique_ptr< amrex::MultiFab > &mf_DU_avg1, std::unique_ptr< amrex::MultiFab > &mf_DU_avg2, std::unique_ptr< amrex::MultiFab > &mf_DV_avg1, std::unique_ptr< amrex::MultiFab > &mf_DV_avg2, std::unique_ptr< amrex::MultiFab > &mf_ubar, std::unique_ptr< amrex::MultiFab > &mf_vbar, std::unique_ptr< amrex::MultiFab > &mf_Akv, std::unique_ptr< amrex::MultiFab > &mf_Akt, std::unique_ptr< amrex::MultiFab > &mf_Hz, std::unique_ptr< amrex::MultiFab > &mf_Huon, std::unique_ptr< amrex::MultiFab > &mf_Hvom, std::unique_ptr< amrex::MultiFab > &mf_z_w, amrex::MultiFab const *mf_h, amrex::MultiFab const *mf_pm, amrex::MultiFab const *mf_pn, amrex::MultiFab const *mf_mskr, amrex::MultiFab const *mf_msku, amrex::MultiFab const *mf_mskv, const int N, const amrex::Real dt_lev) |
| Advance the 3D variables. | |
| void | bulk_fluxes (int lev, amrex::MultiFab *mf_cons, amrex::MultiFab *mf_uwind, amrex::MultiFab *mf_vwind, amrex::MultiFab *mf_Tair, amrex::MultiFab *mf_qair, amrex::MultiFab *mf_Pair, amrex::MultiFab *mf_srflx, amrex::MultiFab *mf_longwave_down, amrex::MultiFab *mf_evap, amrex::MultiFab *mf_sustr, amrex::MultiFab *mf_svstr, amrex::MultiFab *mf_stflux, amrex::MultiFab *mf_lrflx, amrex::MultiFab *mf_lhflx, amrex::MultiFab *mf_shflx, const int N) |
| Calculate bulk temperature, salinity, wind fluxes. | |
| void | prestep (int lev, amrex::MultiFab &mf_uold, amrex::MultiFab &mf_vold, amrex::MultiFab &mf_u, amrex::MultiFab &mf_v, amrex::MultiFab *mf_ru, amrex::MultiFab *mf_rv, amrex::MultiFab &S_old, amrex::MultiFab &S_new, amrex::MultiFab &mf_W, amrex::MultiFab &mf_DC, const amrex::MultiFab *mf_z_r, const amrex::MultiFab *mf_z_w, const amrex::MultiFab *mf_h, const amrex::MultiFab *mf_pm, const amrex::MultiFab *mf_pn, const amrex::MultiFab *mf_sustr, const amrex::MultiFab *mf_svstr, const amrex::MultiFab *mf_bustr, const amrex::MultiFab *mf_bvstr, const amrex::MultiFab *mf_msku, const amrex::MultiFab *mf_mskv, const int iic, const int nfirst, const int nnew, int nstp, int nrhs, int N, const amrex::Real dt_lev) |
| Wrapper function for prestep. | |
| void | prestep_t_advection (int lev, const amrex::Box &tbx, const amrex::Box &gbx, const amrex::Array4< amrex::Real > &tempold, const amrex::Array4< amrex::Real > &tempcache, const amrex::Array4< amrex::Real > &Hz, const amrex::Array4< amrex::Real > &Huon, const amrex::Array4< amrex::Real > &Hvom, const amrex::Array4< amrex::Real > &W, const amrex::Array4< amrex::Real > &DC, const amrex::Array4< amrex::Real > &FC, const amrex::Array4< amrex::Real > &sstore, const amrex::Array4< amrex::Real const > &z_w, const amrex::Array4< amrex::Real const > &h, const amrex::Array4< amrex::Real const > &pm, const amrex::Array4< amrex::Real const > &pn, const amrex::Array4< amrex::Real const > &msku, const amrex::Array4< amrex::Real const > &mskv, const amrex::Array4< int const > &river_pos, const amrex::Array4< amrex::Real const > &river_source, int iic, int ntfirst, int nrhs, int N, const amrex::Real dt_lev) |
| Prestep advection calculations for the tracers. | |
| void | rhs_t_3d (int lev, const amrex::Box &bx, const amrex::Array4< amrex::Real > &t, const amrex::Array4< amrex::Real const > &tempstore, const amrex::Array4< amrex::Real const > &Huon, const amrex::Array4< amrex::Real const > &Hvom, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &pn, const amrex::Array4< amrex::Real const > &pm, const amrex::Array4< amrex::Real const > &W, const amrex::Array4< amrex::Real > &FC, const amrex::Array4< amrex::Real const > &mskr, const amrex::Array4< amrex::Real const > &msku, const amrex::Array4< amrex::Real const > &mskv, const amrex::Array4< int const > &river_pos, const amrex::Array4< amrex::Real const > &river_source, int nrhs, int nnew, int N, const amrex::Real dt_lev) |
| RHS terms for tracer. | |
| void | rhs_uv_3d (int lev, const amrex::Box &xbx, const amrex::Box &ybx, const amrex::Array4< amrex::Real const > &uold, const amrex::Array4< amrex::Real const > &vold, const amrex::Array4< amrex::Real > &ru, const amrex::Array4< amrex::Real > &rv, const amrex::Array4< amrex::Real > &rufrc, const amrex::Array4< amrex::Real > &rvfrc, const amrex::Array4< amrex::Real const > &sustr, const amrex::Array4< amrex::Real const > &svstr, const amrex::Array4< amrex::Real const > &bustr, const amrex::Array4< amrex::Real const > &bvstr, const amrex::Array4< amrex::Real const > &Huon, const amrex::Array4< amrex::Real const > &Hvom, const amrex::Array4< amrex::Real const > &pm, const amrex::Array4< amrex::Real const > &pn, const amrex::Array4< amrex::Real const > &W, const amrex::Array4< amrex::Real > &FC, int nrhs, int N) |
| RHS terms for 3D momentum. | |
| void | rhs_uv_2d (int lev, const amrex::Box &xbx, const amrex::Box &ybx, const amrex::Array4< amrex::Real const > &uold, const amrex::Array4< amrex::Real const > &vold, const amrex::Array4< amrex::Real > &ru, const amrex::Array4< amrex::Real > &rv, const amrex::Array4< amrex::Real const > &Duon, const amrex::Array4< amrex::Real const > &Dvom, const int nrhs) |
| RHS terms for 2D momentum. | |
| void | rho_eos (const amrex::Box &bx, const amrex::Array4< amrex::Real const > &state, const amrex::Array4< amrex::Real > &rho, const amrex::Array4< amrex::Real > &rhoA, const amrex::Array4< amrex::Real > &rhoS, const amrex::Array4< amrex::Real > &bvf, const amrex::Array4< amrex::Real > &alpha, const amrex::Array4< amrex::Real > &beta, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &z_w, const amrex::Array4< amrex::Real const > &z_r, const amrex::Array4< amrex::Real const > &h, const amrex::Array4< amrex::Real const > &mskr, const int N) |
| Wrapper around equation of state calculation. | |
| void | lin_eos (const amrex::Box &bx, const amrex::Array4< amrex::Real const > &state, const amrex::Array4< amrex::Real > &rho, const amrex::Array4< amrex::Real > &rhoA, const amrex::Array4< amrex::Real > &rhoS, const amrex::Array4< amrex::Real > &bvf, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &z_w, const amrex::Array4< amrex::Real const > &z_r, const amrex::Array4< amrex::Real const > &h, const amrex::Array4< amrex::Real const > &mskr, const int N) |
| Calculate density and related quantities from linear equation of state. | |
| void | nonlin_eos (const amrex::Box &bx, const amrex::Array4< amrex::Real const > &state, const amrex::Array4< amrex::Real > &rho, const amrex::Array4< amrex::Real > &rhoA, const amrex::Array4< amrex::Real > &rhoS, const amrex::Array4< amrex::Real > &bvf, const amrex::Array4< amrex::Real > &alpha, const amrex::Array4< amrex::Real > &beta, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &z_w, const amrex::Array4< amrex::Real const > &z_r, const amrex::Array4< amrex::Real const > &h, const amrex::Array4< amrex::Real const > &mskr, const int N) |
| Calculate density and related quantities from nonlinear equation of state. | |
| void | prsgrd (const amrex::Box &bx, const amrex::Box &gbx, const amrex::Box &utbx, const amrex::Box &vtbx, const amrex::Array4< amrex::Real > &ru, const amrex::Array4< amrex::Real > &rv, const amrex::Array4< amrex::Real const > &pn, const amrex::Array4< amrex::Real const > &pm, const amrex::Array4< amrex::Real const > &rho, const amrex::Array4< amrex::Real > &FC, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &z_r, const amrex::Array4< amrex::Real const > &z_w, const amrex::Array4< amrex::Real const > &msku, const amrex::Array4< amrex::Real const > &mskv, const int nrhs, const int N) |
| Calculate pressure gradient. | |
| void | prestep_diffusion (const amrex::Box &bx, const amrex::Box &gbx, const int ioff, const int joff, const amrex::Array4< amrex::Real > &vel, const amrex::Array4< amrex::Real const > &vel_old, const amrex::Array4< amrex::Real > &rvel, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &Akv, const amrex::Array4< amrex::Real > &FC, const amrex::Array4< amrex::Real const > &sstr, const amrex::Array4< amrex::Real const > &bstr, const amrex::Array4< amrex::Real const > &z_r, const amrex::Array4< amrex::Real const > &pm, const amrex::Array4< amrex::Real const > &pn, const int iic, const int ntfirst, const int nnew, int nstp, int nrhs, int N, const amrex::Real lambda, const amrex::Real dt_lev) |
| Update velocities or tracers with diffusion/viscosity as the last part of the prestep. | |
| void | vert_visc_3d (const amrex::Box &bx, const int ioff, const int joff, const amrex::Array4< amrex::Real > &phi, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real > &Hzk, const amrex::Array4< amrex::Real > &AK, const amrex::Array4< amrex::Real const > &Akv, const amrex::Array4< amrex::Real > &BC, const amrex::Array4< amrex::Real > &DC, const amrex::Array4< amrex::Real > &FC, const amrex::Array4< amrex::Real > &CF, const int nnew, const int N, const amrex::Real dt_lev) |
| Calculate effects of vertical viscosity or diffusivity. | |
| void | update_massflux_3d (int lev, const amrex::Box &bx, const int ioff, const int joff, const amrex::Array4< amrex::Real > &phi, const amrex::Array4< amrex::Real > &phibar, const amrex::Array4< amrex::Real > &Hphi, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &pm_or_pn, const amrex::Array4< amrex::Real const > &Dphi1, const amrex::Array4< amrex::Real const > &Dphi2, const amrex::Array4< amrex::Real > &DC, const amrex::Array4< amrex::Real > &FC, const amrex::Array4< amrex::Real const > &msk, const int nnew) |
| Correct mass flux. | |
| void | vert_mean_3d (const amrex::Box &bx, const int ioff, const int joff, const amrex::Array4< amrex::Real > &phi, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &Dphi_avg1, const amrex::Array4< amrex::Real > &DC, const amrex::Array4< amrex::Real > &CF, const amrex::Array4< amrex::Real const > &pm_or_pn, const amrex::Array4< amrex::Real const > &msk, const int nnew, const int N) |
| Adjust 3D momentum variables based on vertical mean momentum. | |
| void | uv3dmix (const amrex::Box &xbx, const amrex::Box &ybx, const amrex::Array4< amrex::Real > &u, const amrex::Array4< amrex::Real > &v, const amrex::Array4< amrex::Real const > &uold, const amrex::Array4< amrex::Real const > &vold, const amrex::Array4< amrex::Real > &rufrc, const amrex::Array4< amrex::Real > &rvfrc, const amrex::Array4< amrex::Real const > &visc2_p, const amrex::Array4< amrex::Real const > &visc2_r, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &pm, const amrex::Array4< amrex::Real const > &pn, const amrex::Array4< amrex::Real const > &mskp, int nrhs, int nnew, const amrex::Real dt_lev) |
| Harmonic viscosity. | |
| void | t3dmix2 (const amrex::Box &bx, const amrex::Array4< amrex::Real > &state, const amrex::Array4< amrex::Real > &state_rhs, const amrex::Array4< amrex::Real const > &diff2, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &z_r, const amrex::Array4< amrex::Real const > &pm, const amrex::Array4< amrex::Real const > &pn, const amrex::Array4< amrex::Real const > &msku, const amrex::Array4< amrex::Real const > &mskv, const amrex::Real dt_lev, const int ncomp, const int N) |
| Wrapper for harmonic diffusivity for tracers. | |
| void | t3dmix2_s (const amrex::Box &bx, const amrex::Array4< amrex::Real > &state, const amrex::Array4< amrex::Real > &state_rhs, const amrex::Array4< amrex::Real const > &diff2, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &pm, const amrex::Array4< amrex::Real const > &pn, const amrex::Array4< amrex::Real const > &msku, const amrex::Array4< amrex::Real const > &mskv, const amrex::Real dt_lev, const int ncomp) |
| Harmonic diffusivity for tracers along S-coordinate level surfaces. | |
| void | t3dmix2_geo (const amrex::Box &bx, const amrex::Array4< amrex::Real > &state, const amrex::Array4< amrex::Real > &state_rhs, const amrex::Array4< amrex::Real const > &diff2, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &z_r, const amrex::Array4< amrex::Real const > &pm, const amrex::Array4< amrex::Real const > &pn, const amrex::Array4< amrex::Real const > &msku, const amrex::Array4< amrex::Real const > &mskv, const amrex::Real dt_lev, const int ncomp, const int N) |
| Harmonic diffusivity for tracers along geopotential surfaces. | |
| void | coriolis (const amrex::Box &xbx, const amrex::Box &ybx, const amrex::Array4< amrex::Real const > &uold, const amrex::Array4< amrex::Real const > &vold, const amrex::Array4< amrex::Real > &ru, const amrex::Array4< amrex::Real > &rv, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &fomn, int nrhs, int nr) |
| Calculate Coriolis terms. | |
| void | curvilinear (const amrex::Box &bx, const amrex::Box &xbx, const amrex::Box &ybx, const amrex::Array4< amrex::Real const > &uold, const amrex::Array4< amrex::Real const > &vold, const amrex::Array4< amrex::Real > &ru, const amrex::Array4< amrex::Real > &rv, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &dndx, const amrex::Array4< amrex::Real const > &dmde, int nrhs, int nr) |
| Calculate curvilinear advection terms. | |
| void | apply_clim_nudg (const amrex::Box &bx, int ioff, int joff, const amrex::Array4< amrex::Real > &var, const amrex::Array4< amrex::Real const > &var_old, const amrex::Array4< amrex::Real const > &var_clim, const amrex::Array4< amrex::Real const > &clim_coeff, const amrex::Array4< amrex::Real const > &Hz, const amrex::Array4< amrex::Real const > &pm, const amrex::Array4< amrex::Real const > &pn, const amrex::Real dt_lev=amrex::Real(0.0)) |
| Apply climatology nudging. | |
| void | set_2darrays (int lev) |
| Set 2D momentum arrays from 3D momentum. | |
| void | set_zeta_average (int lev) |
| Set Zt_avg1 to zeta. | |
| void | set_zeta (int lev) |
| Initialize zeta from file or analytic. | |
| void | set_zeta_averaged_down (int lev) |
| Copy over zeta data that has been averaged down from high res. | |
| void | set_bathymetry (int lev) |
| Initialize bathymetry from file or analytic. | |
| void | set_bathymetry_averaged_down (int lev) |
| Copy over bathymetry data that has been averaged down from high resolution input netcdf file. | |
| void | set_coriolis (int lev) |
| Initialize Coriolis factor from file or analytic. | |
| void | set_masks (int lev) |
| Initialize land-sea masks from file or analytic. | |
| void | stretch_transform (int lev) |
| Calculate vertical stretched coordinates. | |
| void | init_set_vmix (int lev) |
| Initialize vertical mixing coefficients from file or analytic. | |
| void | set_analytic_vmix (int lev) |
| Set vertical mixing coefficients from analytic. | |
| void | init_gls_vmix (int lev, SolverChoice solver_choice) |
| Initialize GLS variables. | |
| void | gls_prestep (int lev, amrex::MultiFab *mf_gls, amrex::MultiFab *mf_tke, amrex::MultiFab &mf_W, amrex::MultiFab *mf_msku, amrex::MultiFab *mf_mskv, const int nstp, const int nnew, const int iic, const int ntfirst, const int N, const amrex::Real dt_lev) |
| Prestep for GLS calculation. | |
| void | gls_corrector (int lev, amrex::MultiFab *mf_gls, amrex::MultiFab *mf_tke, amrex::MultiFab &mf_W, amrex::MultiFab *mf_Akv, amrex::MultiFab *mf_Akt, amrex::MultiFab *mf_Akk, amrex::MultiFab *mf_Akp, amrex::MultiFab *mf_mskr, amrex::MultiFab *mf_msku, amrex::MultiFab *mf_mskv, const int nstp, const int nnew, const int N, const amrex::Real dt_lev) |
| Corrector step for GLS calculation. | |
| void | scale_rhs_vars () |
| Scale RHS momentum variables by 1/cell area, needed before FillPatch to different levels. | |
| void | scale_rhs_vars_inv () |
| Scale RHS momentum variables by cell area, needed after FillPatch to different levels. | |
| void | set_smflux (int lev) |
| Initialize or calculate surface momentum flux from file or analytic. | |
| void | set_wind (int lev) |
| Initialize or calculate wind speed from file or analytic. | |
| void | set_hmixcoef (int lev) |
| Initialize horizontal mixing coefficients. | |
| void | init_flat_bathymetry (int lev) |
| Initialize flat bathymetry to value from problo. | |
| void | set_drag (int lev) |
| Initialize or calculate bottom drag. | |
| void | set_weights (int lev) |
| Set weights for averaging 3D variables to 2D. | |
| void | FillBdyCCVels (int lev, amrex::MultiFab &mf_cc_vel) |
| Fill the physical boundary conditions for cell-centered velocity (diagnostic only) | |
| void | FillPatch (int lev, amrex::Real time, amrex::MultiFab &mf_to_be_filled, amrex::Vector< amrex::MultiFab * > const &mfs, const int bccomp, const int bdy_var_type=BdyVars::null, const int icomp=0, const bool fill_all=true, const bool fill_set=true, const int n_not_fill=0, const int icomp_calc=0, const amrex::Real dt=amrex::Real(0.0), const amrex::MultiFab &mf_calc=amrex::MultiFab()) |
| Fill a new MultiFab by copying in phi from valid region and filling ghost cells. | |
| void | FillPatchNoBC (int lev, amrex::Real time, amrex::MultiFab &mf_to_be_filled, amrex::Vector< amrex::MultiFab * > const &mfs, const int bdy_var_type=BdyVars::null, const int icomp=0, const bool fill_all=true, const bool fill_set=true) |
| Fill a new MultiFab by copying in phi from valid region and filling ghost cells without applying boundary conditions. | |
| void | fill_from_bdyfiles (int lev, amrex::MultiFab &mf_to_fill, const amrex::MultiFab &mf_mask, const amrex::Real time, const int bccomp, const int bdy_var_type, const int icomp_to_fill, const int icomp_calc=0, const amrex::MultiFab &mf_calc=amrex::MultiFab(), const amrex::Real=amrex::Real(0.0)) |
| Fill boundary data from netcdf file. | |
| void | FillCoarsePatchPC (int lev, amrex::Real time, amrex::MultiFab *mf_fine, amrex::MultiFab *mf_crse, const int bccomp, const int bdy_var_type=BdyVars::null, const int icomp=0, const bool fill_all=true, const int n_not_fill=0, const int icomp_calc=0, const amrex::Real dt=amrex::Real(0.0), const amrex::MultiFab &mf_calc=amrex::MultiFab()) |
| fill an entire multifab by interpolating from the coarser level using the piecewise constant interpolater | |
| void | FillCoarsePatch (int lev, amrex::Real time, amrex::MultiFab *mf_fine, amrex::MultiFab *mf_crse, const int bccomp, const int bdy_var_type=BdyVars::null, const int icomp=0, const bool fill_all=true, const int n_not_fill=0, const int icomp_calc=0, const amrex::Real dt=amrex::Real(0.0), const amrex::MultiFab &mf_calc=amrex::MultiFab()) |
| fill an entire multifab by interpolating from the coarser level | |
| void | FillCoarsePatchMap (int lev, amrex::Real time, amrex::MultiFab *mf_fine, amrex::MultiFab *mf_crse, const int bccomp, const int bdy_var_type=BdyVars::null, const int icomp=0, const bool fill_all=true, const int n_not_fill=0, const int icomp_calc=0, const amrex::Real dt=amrex::Real(0.0), const amrex::MultiFab &mf_calc=amrex::MultiFab(), amrex::Interpolater *mapper=nullptr) |
| fill an entire multifab by interpolating from the coarser level, explicitly specifying interpolator to use | |
| void | init_stretch_coeffs () |
| initialize and calculate stretch coefficients | |
| void | calc_stretch_coeffs () |
| calculate vertical stretch coefficients | |
| void | init_beta_plane_coriolis (int lev) |
| Calculate Coriolis parameters from beta plane parametrization. | |
| void | init_bathymetry_full_domain_from_analytic () |
| Full domain bathymetry data initialization from analytic. | |
| void | set_init_data_averaged_down (int lev) |
| Problem initialization from averaged-down high resolution data. | |
| void | init_data_from_netcdf (int lev) |
| Problem initialization from NetCDF file. | |
| void | init_data_full_domain_from_netcdf () |
| High resolution roblem initialization from NetCDF file. | |
| void | init_bdry_from_netcdf (int lev) |
| Boundary data initialization from NetCDF file. | |
| void | init_masks_from_netcdf (int lev) |
| Mask data initialization from NetCDF file. | |
| void | init_bathymetry_from_netcdf (int lev) |
| Bathymetry data initialization from NetCDF file. | |
| void | init_bathymetry_full_domain_from_netcdf () |
| Full domain high-res bathymetry data initialization from NetCDF file. | |
| void | init_grid_vars_from_netcdf (int lev) |
| Grid variable initialization from NetCDF file. | |
| void | init_grid_vars_full_domain_from_netcdf () |
| Full domain high-res grid variable initialization from NetCDF file. | |
| void | extrapolate_metric_to_physical_boundaries (amrex::MultiFab &mf, const amrex::Geometry &geom) |
| Extrapolate grid metrics to edge of MultiFab. | |
| void | init_zeta_from_netcdf (int lev) |
| Sea-surface height data initialization from NetCDF file. | |
| void | init_zeta_full_domain_from_netcdf () |
| Full-domain high res sea-surface height data initialization from NetCDF file. | |
| void | init_coriolis_from_netcdf (int lev) |
| Coriolis parameter data initialization from NetCDF file. | |
| void | init_clim_nudg_coeff_from_netcdf (int lev) |
| Climatology nudging coefficient initialization from NetCDF file. | |
| void | init_clim_nudg_coeff (int lev) |
| Wrapper to initialize climatology nudging coefficient. | |
| void | init_riv_pos_from_netcdf (int lev) |
| void | allocate_bathymetry_grid_vars_full_domain () |
| Allocate multifabs for storing full-domain bathymetry and grid vars data. | |
| void | allocate_init_full_domain () |
| Allocate multifabs for storing full-domain high resolution initial data. | |
| void | convert_inv_days_to_inv_s (amrex::MultiFab *) |
| Convert data in a multifab from inverse days to inverse seconds. | |
| void | mask_arrays_for_write (int lev, amrex::Real fill_value, amrex::Real fill_where) |
| Mask data arrays before writing output. | |
| void | average_down_with_grow_cells (int lev, amrex::Vector< std::unique_ptr< amrex::MultiFab > > &mf) |
| Average down from level lev+1 to lev in mf, including grow cells. | |
| int | xvel_bc () const noexcept |
| int | yvel_bc () const noexcept |
| int | zvel_bc () const noexcept |
| int | ubar_bc () const noexcept |
| int | vbar_bc () const noexcept |
| int | zeta_bc () const noexcept |
| int | tke_bc () const noexcept |
| int | foextrap_periodic_bc () const noexcept |
| int | foextrap_bc () const noexcept |
| int | u2d_simple_bc () const noexcept |
| int | v2d_simple_bc () const noexcept |
| int | num_bc_vars () const noexcept |
| void | writeJobInfo (const std::string &dir) const |
| Write job info to stdout. | |
| amrex::Real | get_t_old (int lev) const |
| Accessor method for t_old to expose to outside classes. | |
Static Public Member Functions | |
| static void | writeBuildInfo (std::ostream &os) |
| Write build info to os. | |
| static void | print_banner (MPI_Comm, std::ostream &) |
| static void | print_usage (MPI_Comm, std::ostream &) |
| static void | print_error (MPI_Comm, const std::string &msg) |
| static void | print_summary (std::ostream &) |
| static void | print_tpls (std::ostream &) |
| AMREX_GPU_HOST_DEVICE static AMREX_FORCE_INLINE amrex::Real | bulk_psiu (amrex::Real ZoL) |
| Evaluate stability function psi for wind speed. | |
| AMREX_GPU_HOST_DEVICE static AMREX_FORCE_INLINE amrex::Real | bulk_psit (amrex::Real ZoL) |
| Evaluate stability function psi for moisture and heat. | |
Public Attributes | |
| std::string | pp_prefix {"remora"} |
| default prefix for input file parameters | |
| amrex::Vector< amrex::MultiFab * > | cons_old |
| multilevel data container for last step's scalar data: temperature, salinity, passive tracer | |
| amrex::Vector< amrex::MultiFab * > | xvel_old |
| multilevel data container for last step's x velocities (u in ROMS) | |
| amrex::Vector< amrex::MultiFab * > | yvel_old |
| multilevel data container for last step's y velocities (v in ROMS) | |
| amrex::Vector< amrex::MultiFab * > | zvel_old |
| multilevel data container for last step's z velocities (largely unused; W stored separately) | |
| amrex::Vector< amrex::MultiFab * > | cons_new |
| multilevel data container for current step's scalar data: temperature, salinity, passive tracer | |
| amrex::Vector< amrex::MultiFab * > | xvel_new |
| multilevel data container for current step's x velocities (u in ROMS) | |
| amrex::Vector< amrex::MultiFab * > | yvel_new |
| multilevel data container for current step's y velocities (v in ROMS) | |
| amrex::Vector< amrex::MultiFab * > | zvel_new |
| multilevel data container for current step's z velocities (largely unused; W stored separately) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_cons_full_domain |
| multilevel data container for high res initial data: temperature, salinity, passive tracer | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_xvel_full_domain |
| multilevel data container for high res initial x velocities (u in ROMS) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_yvel_full_domain |
| multilevel data container for high res initial y velocities (v in ROMS) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_h |
| multilevel data container for current step's z velocities (largely unused; W stored separately) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_h_full_domain |
| Bathymetry data on the whole domain at each potential level. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Hz |
| Width of cells in the vertical (z-) direction (3D, Hz in ROMS) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Huon |
| u-volume flux (3D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Hvom |
| v-volume flux (3D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_ru |
| u velocity RHS (3D, includes horizontal and vertical advection) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rv |
| v velocity RHS (3D, includes horizontal and vertical advection) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_ru2d |
| u velocity RHS (2D, includes horizontal and vertical advection) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rv2d |
| v velocity RHS (2D, includes horizontal and vertical advection) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rufrc |
| u velocity RHS, integrated, including advection and bottom/surface stresses (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rvfrc |
| v velocity RHS, integrated, including advection and bottom/surface stresses (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Akv |
| Vertical viscosity coefficient (3D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Akt |
| Vertical diffusion coefficient (3D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_visc2_p |
| Harmonic viscosity defined on the psi points (corners of horizontal grid cells) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_visc2_r |
| Harmonic viscosity defined on the rho points (centers) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_diff2 |
| Harmonic diffusivity for temperature / salinity. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_z_r |
| z coordinates at rho points (cell centers) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_z_w |
| z coordinates at w points (faces between z-cells) | |
| amrex::Gpu::DeviceVector< amrex::Real > | s_r |
| Scaled vertical coordinate (range [0,1]) that transforms to z, defined at rho points (cell centers) | |
| amrex::Gpu::DeviceVector< amrex::Real > | s_w |
| Scaled vertical coordinate (range [0,1]) that transforms to z, defined at w-points (cell faces) | |
| amrex::Gpu::DeviceVector< amrex::Real > | Cs_r |
| Stretching coefficients at rho points. | |
| amrex::Gpu::DeviceVector< amrex::Real > | Cs_w |
| Stretching coefficients at w points. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_z_phys_nd |
| z coordinates at psi points (cell nodes) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Zt_avg1 |
| Average of the free surface, zeta (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_sustr |
| Surface stress in the u direction. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_svstr |
| Surface stress in the v direction. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_uwind |
| Wind in the u direction, defined at rho-points. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_vwind |
| Wind in the v direction, defined at rho-points. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Tair |
| Air temperature [°C], defined at rho-points. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_qair |
| Specific humidity [kg/kg], defined at rho-points. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Pair |
| Air pressure [mb], defined at rho-points. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_srflx |
| Shortwave radiation flux [W/m²], defined at rho-points. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_lrflx |
| longwave radiation | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_longwave_down |
| Downward longwave radiation. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_lhflx |
| latent heat flux | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_shflx |
| sensible heat flux | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_stflx |
| Surface tracer flux; working arrays. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_stflux |
| Surface tracer flux; input arrays. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_btflx |
| Bottom tracer flux; working arrays. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_btflux |
| Bottom tracer flux; input arrays. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rain |
| precipitation rate [kg/m^2/s] | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_evap |
| evaporation rate [kg/m^2/s] | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_cloud |
| cloud cover fraction [0-1], defined at rho-points | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_EminusP |
| evaporation minus precipitation [kg/m^2/s], defined at rho-points | |
| std::array< bool, AtmosState::NumTypes > | driver_atmos_state_from_driver {} |
| provenance flags for driver-supplied atmospheric forcing lanes | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rdrag |
| Linear drag coefficient [m/s], defined at rho points. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rdrag2 |
| Quadratic drag coefficient [unitless], defined at rho points. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_ZoBot |
| Bottom roughness length [m], defined at rho points. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_bustr |
| Bottom stress in the u direction. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_bvstr |
| Bottom stress in the v direction. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_DU_avg1 |
| time average of barotropic x velocity flux (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_DU_avg2 |
| correct time average of barotropic x velocity flux for coupling (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_DV_avg1 |
| time average of barotropic y velocity flux | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_DV_avg2 |
| correct time average of barotropic y velocity flux for coupling (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rubar |
| barotropic x velocity for the RHS (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rvbar |
| barotropic y velocity for the RHS (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rzeta |
| free surface height for the RHS (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_ubar |
| barotropic x velocity (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_vbar |
| barotropic y velocity (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_zeta |
| free surface height (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_zeta_full_domain |
| high resolution initial free surface height (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_mskr |
| land/sea mask at cell centers (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_msku |
| land/sea mask at x-faces (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_mskv |
| land/sea mask at y-faces (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_mskp |
| land/sea mask at cell corners (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_mskr3d |
| land/sea mask at cell centers, copied to all z levels (3D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_pm |
| horizontal scaling factor: 1 / dx (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_pn |
| horizontal scaling factor: 1 / dy (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_pm_full_domain |
| horizontal scaling factor: 1 / dx (2D) on whole domain | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_pn_full_domain |
| horizontal scaling factor: 1 / dy (2D) on whole domain | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_fcor |
| coriolis factor (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_xr |
| x_grid on rho points (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_yr |
| y_grid on rho points (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_xu |
| x_grid on u-points (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_yu |
| y_grid on u-points (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_xv |
| x_grid on v-points (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_yv |
| y_grid on v-points (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_xp |
| x_grid on psi-points (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_yp |
| y_grid on psi-points (2D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_dndx |
| d(1/n)/d(xi) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_dmde |
| d(1/m)/d(eta) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_sstore |
| additional scratch space for calculations on temp, salt, etc | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rhoS |
| density perturbation | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_rhoA |
| vertically-averaged density | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_bvf |
| Brunt-Vaisala frequency (3D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_alpha |
| Thermal expansion coefficient (3D) | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_beta |
| Saline contraction coefficient (3D) | |
| amrex::Vector< amrex::Real > | vec_weight1 |
| Weights for calculating avg1 in 2D advance. | |
| amrex::Vector< amrex::Real > | vec_weight2 |
| Weights for calculating avg2 in 2D advance. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_tke |
| Turbulent kinetic energy. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_gls |
| Turbulent generic length scale. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Lscale |
| Vertical mixing turbulent length scale. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Akk |
| Turbulent kinetic energy vertical diffusion coefficient. | |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > | vec_Akp |
| Turbulent length scale vertical diffusion coefficient. | |
| amrex::Vector< amrex::Vector< std::unique_ptr< amrex::MultiFab > > > | vec_nudg_coeff |
| Climatology nudging coefficients. | |
Static Public Attributes | |
| static int | total_nc_plot_file_step = 1 |
Private Member Functions | |
| void | ReadParameters () |
| read in some parameters from inputs file | |
| void | init_scalar_metadata () |
| Build runtime scalar names after nscalar is known. | |
| void | AverageDown () |
| set covered coarse cells to be the average of overlying fine cells | |
| void | init_bcs () |
| Read in boundary parameters from input file and set up data structures. | |
| void | init_analytic (int lev) |
| Initialize initial problem data from analytic functions. | |
| void | init_full_domain_from_analytic () |
| Initialize high resolution initial problem data from analytic functions. | |
| void | init_full_domain_zeta_from_analytic () |
| Initialize high resolution initial sea surface height from analytic functions. | |
| void | init_stuff (int lev, const amrex::BoxArray &ba, const amrex::DistributionMapping &dm) |
| Allocate MultiFabs for state and evolution variables. | |
| void | init_masks (int lev, const amrex::BoxArray &ba, const amrex::DistributionMapping &dm) |
| Allocate MultiFabs for masks. | |
| void | resize_stuff (int lev) |
| Resize variable containers to accommodate data on levels 0 to max_lev. | |
| void | AverageDownTo (int crse_lev) |
| more flexible version of AverageDown() that lets you average down across multiple levels | |
| void | Construct_REMORAFillPatchers (int lev) |
| Construct FillPatchers. | |
| void | Define_REMORAFillPatchers (int lev) |
| Define FillPatchers. | |
| TimeInterpolatedData | GetDataAtTime (int lev, amrex::Real time) |
| utility to copy in data from old and/or new state into another multifab | |
| void | timeStep (int lev, amrex::Real time, int iteration) |
| advance a level by dt, includes a recursive call for finer levels | |
| void | timeStepML (amrex::Real time, int iteration) |
| advance all levels by dt, loops over finer levels | |
| void | ComputeDt () |
| a wrapper for estTimeStep() | |
| std::string | PlotFileName (int lev) const |
| get plotfile name | |
| void | set2DPlotVariables (const std::string &pp_plot_var_names_2d) |
| void | set3DPlotVariables (const std::string &pp_plot_var_names_3d) |
| void | append2DPlotVariables (const std::string &pp_plot_var_names_2d) |
| void | append3DPlotVariables (const std::string &pp_plot_var_names_3d) |
| void | WriteNCPlotFile (int istep, amrex::MultiFab const *plotMF) |
| Write plotfile using NetCDF (wrapper) | |
| void | WriteNCPlotFile_which (int lev, int which_subdomain, amrex::MultiFab const *plotMF, bool write_header, ncutils::NCFile &ncf, bool is_history) |
| Write a particular NetCDF plotfile. | |
| void | WriteNCMultiFab (const amrex::FabArray< amrex::FArrayBox > &fab, const std::string &name, bool set_ghost=false) const |
| Write MultiFab in NetCDF format. | |
| void | ReadNCMultiFab (amrex::FabArray< amrex::FArrayBox > &fab, const std::string &name, int coordinatorProc=amrex::ParallelDescriptor::IOProcessorNumber(), int allow_empty_mf=0) |
| Read MultiFab in NetCDF format. | |
| void | WriteCheckpointFile () |
| write checkpoint file to disk | |
| void | ReadCheckpointFile () |
| read checkpoint file from disk | |
| void | InitializeFromFile () |
| Read the file passed to remora.restart and use it as an initial condition for the current simulation. | |
| void | InitializeLevelFromData (int lev, const amrex::MultiFab &initial_data) |
| Initialize the new-time data at a level from the initial_data MultiFab. | |
| void | refinement_criteria_setup () |
| Set refinement criteria. | |
| AMREX_FORCE_INLINE int | ComputeGhostCells (const int &spatial_order) |
| Helper function to determine number of ghost cells. | |
| AMREX_FORCE_INLINE std::ostream & | DataLog (int i) |
| Helper function for IO stream. | |
| AMREX_FORCE_INLINE int | NumDataLogs () noexcept |
| amrex::Real | getCPUTime () const |
| Get CPU time used. | |
| void | setRecordDataInfo (int i, const std::string &filename) |
| const std::string | DataLogName (int i) const noexcept |
| The filename of the ith datalog file. | |
Static Private Member Functions | |
| static void | GotoNextLine (std::istream &is) |
| utility to skip to next line in Header | |
Private Attributes | |
| amrex::Real | start_bdy_time |
| Start time in the time series of boundary data. | |
| amrex::Real | bdy_time_interval |
| Interval between boundary data times. | |
| std::unique_ptr< NCTimeSeries > | sustr_data_from_file |
| Data container for u-component surface momentum flux read from file. | |
| std::unique_ptr< NCTimeSeries > | svstr_data_from_file |
| Data container for v-component surface momentum flux read from file. | |
| std::unique_ptr< NCTimeSeries > | Uwind_data_from_file |
| Data container for u-direction wind read from file. | |
| std::unique_ptr< NCTimeSeries > | Vwind_data_from_file |
| Data container for v-direction wind read from file. | |
| std::unique_ptr< NCTimeSeries > | Tair_data_from_file |
| Data container for air temperature read from file. | |
| std::unique_ptr< NCTimeSeries > | qair_data_from_file |
| Data container for specific humidity read from file. | |
| std::unique_ptr< NCTimeSeries > | Pair_data_from_file |
| Data container for air pressure read from file. | |
| std::unique_ptr< NCTimeSeries > | srflx_data_from_file |
| Data container for shortwave radiation flux read from file. | |
| std::unique_ptr< NCTimeSeries > | longwave_down_data_from_file |
| Data container for downward longwave radiation flux read from file. | |
| std::unique_ptr< NCTimeSeries > | rain_data_from_file |
| Data container for precipitation rate read from file. | |
| std::unique_ptr< NCTimeSeries > | cloud_data_from_file |
| Data container for cloud cover fraction read from file. | |
| std::unique_ptr< NCTimeSeries > | EminusP_data_from_file |
| Data container for evaporation minus precipitation read from file. | |
| std::unique_ptr< NCTimeSeries > | ubar_clim_data_from_file |
| Data container for ubar climatology data read from file. | |
| std::unique_ptr< NCTimeSeries > | vbar_clim_data_from_file |
| Data container for vbar climatology data read from file. | |
| std::unique_ptr< NCTimeSeries > | u_clim_data_from_file |
| Data container for u-velocity climatology data read from file. | |
| std::unique_ptr< NCTimeSeries > | v_clim_data_from_file |
| Data container for v-velocity climatology data read from file. | |
| std::unique_ptr< NCTimeSeries > | temp_clim_data_from_file |
| Data container for temperature climatology data read from file. | |
| std::unique_ptr< NCTimeSeries > | salt_clim_data_from_file |
| Data container for salinity climatology data read from file. | |
| amrex::Vector< std::unique_ptr< NCTimeSeriesRiver > > | river_source_cons |
| Vector of data containers for scalar data in rivers. | |
| std::unique_ptr< NCTimeSeriesRiver > | river_source_transport |
| Data container for momentum transport in rivers. | |
| std::unique_ptr< NCTimeSeriesRiver > | river_source_transportbar |
| Data container for vertically integrated momentum transport in rivers. | |
| amrex::Vector< amrex::Vector< std::unique_ptr< NCTimeSeriesBoundary > > > | boundary_series |
| Vector over BdyVars of boundary series data containers. | |
| amrex::Vector< std::unique_ptr< amrex::iMultiFab > > | vec_river_position |
| iMultiFab for river positions; contents are indices of rivers | |
| amrex::Gpu::DeviceVector< int > | river_direction |
| Vector over rivers of river direction: 0: u-face; 1: v-face; 2: w-face. | |
| int | cf_width {0} |
| Nudging width at coarse-fine interface. | |
| int | cf_set_width {0} |
| Width for fixing values at coarse-fine interface. | |
| amrex::Vector< REMORAFillPatcher > | FPr_c |
| Vector over levels of FillPatchers for scalars. | |
| amrex::Vector< REMORAFillPatcher > | FPr_u |
| Vector over levels of FillPatchers for u (3D) | |
| amrex::Vector< REMORAFillPatcher > | FPr_v |
| Vector over levels of FillPatchers for v (3D) | |
| amrex::Vector< REMORAFillPatcher > | FPr_w |
| Vector over levels of FillPatchers for w. | |
| amrex::Vector< REMORAFillPatcher > | FPr_ubar |
| Vector over levels of FillPatchers for ubar (2D) | |
| amrex::Vector< REMORAFillPatcher > | FPr_vbar |
| Vector over levels of FillPatchers for vbar (2D) | |
| std::unique_ptr< ProblemBase > | prob = nullptr |
| Pointer to container of analytical functions for problem definition. | |
| amrex::Vector< int > | num_boxes_at_level |
| how many boxes specified at each level by tagging criteria | |
| amrex::Vector< int > | num_files_at_level |
| how many netcdf input files specified at each level | |
| amrex::Vector< amrex::Vector< amrex::Box > > | boxes_at_level |
| the boxes specified at each level by tagging criteria | |
| amrex::Vector< int > | istep |
| which step? | |
| amrex::Vector< int > | nsubsteps |
| How many substeps on each level? | |
| amrex::Vector< amrex::Real > | t_new |
| new time at each level | |
| amrex::Vector< amrex::Real > | t_old |
| old time at each level | |
| amrex::Vector< amrex::Real > | dt |
| time step at each level | |
| bool | set_bcs_by_var |
| whether to set boundary conditions by variable rather than just by side | |
| amrex::Vector< std::unique_ptr< REMORAPhysBCFunct > > | physbcs |
| Vector (over level) of functors to apply physical boundary conditions. | |
| amrex::Vector< std::unique_ptr< amrex::YAFluxRegister > > | advflux_reg |
| array of flux registers for refluxing in multilevel | |
| amrex::Vector< amrex::BCRec > | domain_bcs_type |
| vector (over BCVars) of BCRecs | |
| amrex::Gpu::DeviceVector< amrex::BCRec > | domain_bcs_type_d |
| GPU vector (over BCVars) of BCRecs. | |
| amrex::Array< std::string, 2 *AMREX_SPACEDIM > | domain_bc_type |
| Array of strings describing domain boundary conditions. | |
| amrex::Vector< amrex::GpuArray< amrex::Real, AMREX_SPACEDIM *2 > > | m_bc_extdir_vals |
| Array holding the Dirichlet values at walls which need them. | |
| amrex::Vector< amrex::GpuArray< REMORA_BC, AMREX_SPACEDIM *2 > > | phys_bc_type |
| Array holding the "physical" boundary condition types (e.g. "inflow") | |
| amrex::GpuArray< amrex::GpuArray< bool, AMREX_SPACEDIM *2 >, BdyVars::NumTypes+1 > | phys_bc_need_data |
| These are flags that indicate whether we need to read in boundary data from file. | |
| amrex::Vector< int > | bdy_index |
| Container to connect boundary data being read in boundary condition containers. | |
| int | last_plot_file_step |
| Step when we last output a plotfile. | |
| amrex::Real | last_plot_file_time |
| Simulation time when we last output a plotfile. | |
| int | last_check_file_step |
| Step when we last output a checkpoint file. | |
| amrex::Real | last_check_file_time |
| Simulation time when we last output a checkpoint file. | |
| int | plot_file_on_restart = 1 |
| Whether to output a plotfile on restart from checkpoint. | |
| int | max_step = std::numeric_limits<int>::max() |
| maximum number of steps | |
| amrex::Real | stop_time = std::numeric_limits<amrex::Real>::max() |
| Time to stop. | |
| amrex::Real | start_time = 0.0 |
| Time of the start of the simulation, in seconds. | |
| std::string | restart_chkfile = "" |
| If set, restart from this checkpoint file. | |
| int | nscalar = 1 |
| Number of passive scalars carried in the state. | |
| int | ncons = Tracer_comp + 1 |
| Number of conserved scalars in the state (temperature + salt + passive scalars) | |
| int | nfast |
| Number of fast steps to take. | |
| int | do_substep = 0 |
| Whether to substep fine levels in time. | |
| int | regrid_int = 2 |
| how often each level regrids the higher levels of refinement (after a level advances that many time steps) | |
| std::string | plot_file_name {"plt_"} |
| Plotfile prefix. | |
| int | plot_int = -1 |
| Plotfile output interval in iterations. | |
| amrex::Real | plot_int_time = amrex::Real(-1.0) |
| Plotfile output interval in seconds. | |
| std::string | check_file {"chk"} |
| Checkpoint file prefix. | |
| int | check_int = -1 |
| Checkpoint output interval in iterations. | |
| amrex::Real | check_int_time = amrex::Real(-1.0) |
| Checkpoint output interval in seconds. | |
| bool | chunk_history_file = false |
| Whether to chunk netcdf history file. | |
| int | steps_per_history_file = -1 |
| Number of time steps per netcdf history file. | |
| int | history_count = 0 |
| Counter for which time index we are writing to in the netcdf history file. | |
| amrex::Vector< std::string > | plot_var_names_3d |
| Names of 3D variables to output to AMReX plotfile. | |
| amrex::Vector< std::string > | plot_var_names_2d |
| Names of 2D variables to output to AMReX plotfile. | |
| amrex::Vector< std::string > | cons_names {"temp", "salt", "tracer"} |
| Names of scalars for plotfile output. | |
| const amrex::Vector< std::string > | derived_names {"vorticity"} |
| Names of derived fields for plotfiles. | |
| bool | expand_plotvars_to_unif_rr = false |
| whether plotfile variables should be expanded to a uniform refinement ratio | |
| amrex::Real | plotfile_fill_value = amrex::Real(0.0) |
| fill value for masked arrays in amrex plotfiles | |
| amrex::Real | netcdf_fill_value = amrex::Real(1.0e37) |
| fill value for masked arrays in netcdf output | |
| int | hires_grid_level = -1 |
| Which level the high resolution bathymetry is at. | |
| std::string | nc_grid_file_hires |
| Grid file for high resolution bathymetry. | |
| amrex::Box | nc_hires_grid_box |
| Box for the full domain at nc_hires_grid_level. | |
| int | hires_init_level = -1 |
| Which level the high resolution initialization data is at. | |
| std::string | nc_init_file_hires |
| Init file for high resolution. | |
| amrex::Box | nc_hires_init_box |
| Box for the full domain at nc_hires_init_level. | |
| amrex::Vector< amrex::IntVect > | cum_ref_ratios |
| Cumulative refinement ratio between level 0 and level i. | |
| amrex::Vector< std::string > | nc_frc_file |
| NetCDF forcing file(s) | |
| amrex::Vector< std::string > | nc_riv_file |
| NetCDF river file(s) | |
| amrex::Vector< std::string > | nc_clim_his_file |
| NetCDF climatology history file(s) | |
| std::string | nc_clim_coeff_file |
| NetCDF climatology coefficient file. | |
| std::string | bdry_time_varname = "ocean_time" |
| Default name of time field for boundary data. | |
| amrex::Vector< std::string > | bdry_time_name_byvar |
| Name of time fields for boundary data. | |
| std::string | clim_ubar_time_varname = "ocean_time" |
| Name of time field for ubar climatology data. | |
| std::string | clim_vbar_time_varname = "ocean_time" |
| Name of time field for vbar climatology data. | |
| std::string | clim_u_time_varname = "ocean_time" |
| Name of time field for u climatology data. | |
| std::string | clim_v_time_varname = "ocean_time" |
| Name of time field for v climatology data. | |
| std::string | clim_salt_time_varname = "ocean_time" |
| Name of time field for salinity climatology data. | |
| std::string | clim_temp_time_varname = "ocean_time" |
| Name of time field for temperature climatology data. | |
| std::string | riv_time_varname = "river_time" |
| Name of time field for river time. | |
| std::string | frc_time_varname = "" |
| Name of time field for forcing data. | |
| amrex::MultiFab | fine_mask |
| Mask that zeroes out values on a coarse level underlying grids on the next finest level. | |
| amrex::Vector< std::unique_ptr< std::fstream > > | datalog |
| amrex::Vector< std::string > | datalogname |
Static Private Attributes | |
| static bool | write_history_file = true |
| Whether to output NetCDF files as a single history file with several time steps. | |
| static amrex::Real | cfl = 0.8_rt |
| CFL condition. | |
| static amrex::Real | change_max = 1.1_rt |
| Fraction maximum change in subsequent time steps. | |
| static amrex::Real | fixed_dt = -1.0_rt |
| User specified fixed baroclinic time step. | |
| static amrex::Real | fixed_fast_dt = -1.0_rt |
| User specified fixed barotropic time step. | |
| static int | fixed_ndtfast_ratio = 0 |
| User specified, number of barotropic steps per baroclinic step. | |
| static SolverChoice | solverChoice |
| Container for algorithmic choices. | |
| static int | verbose = 0 |
| Verbosity level of output. | |
| static int | sum_interval = -1 |
| Diagnostic sum output interval in number of steps. | |
| static amrex::Real | sum_per = -1.0_rt |
| Diagnostic sum output interval in time. | |
| static int | file_min_digits = 5 |
| Minimum number of digits in plotfile name or chunked history file. | |
| static bool | plot_staggered_vels = false |
| Whether to write the staggered velocities (not averaged to cell centers) | |
| static bool | plot_nodal_data = true |
| Whether to write nodal data (Nu_nd) to plotfiles. | |
| static PlotfileType | plotfile_type = PlotfileType::amrex |
| Native or NetCDF plotfile output. | |
| static amrex::Vector< amrex::Vector< std::string > > | nc_init_file = {{""}} |
| NetCDF initialization file. | |
| static amrex::Vector< amrex::Vector< std::string > > | nc_grid_file = {{""}} |
| NetCDF grid file. | |
| static amrex::Vector< std::string > | nc_bdry_file = {""} |
| NetCDF boundary data. | |
| static amrex::Vector< amrex::AMRErrorTag > | ref_tags |
| Holds info for dynamically generated tagging criteria. | |
| static amrex::Real | startCPUTime = 0.0_rt |
| Variable for CPU timing. | |
| static amrex::Real | previousCPUTimeUsed = 0.0_rt |
| Accumulator variable for CPU time used thusfar. | |
Detailed Description
Class that stores all relevant simulation state data with methods for time stepping.
Constructor & Destructor Documentation
◆ REMORA() [1/2]
| REMORA::REMORA | ( | ) |
constructor:
- reads in parameters from inputs file
- sizes multilevel arrays and data structures
- initializes BCRec boundary condition object
Definition at line 65 of file REMORA.cpp.

◆ REMORA() [2/2]
| REMORA::REMORA | ( | const amrex::RealBox & | rb, |
| int | max_level_in, | ||
| const amrex::Vector< int > & | n_cell_in, | ||
| int | coord, | ||
| const amrex::Vector< amrex::IntVect > & | ref_ratio, | ||
| const amrex::Array< int, AMREX_SPACEDIM > & | is_per, | ||
| std::string | prefix | ||
| ) |

◆ ~REMORA()
|
virtual |
Definition at line 229 of file REMORA.cpp.
Member Function Documentation
◆ Advance()
| void REMORA::Advance | ( | int | lev, |
| amrex::Real | time, | ||
| amrex::Real | dt_lev, | ||
| int | iteration, | ||
| int | ncycle | ||
| ) |
advance a single level for a single time step
- Parameters
-
[in] lev level of refinement [in] time simulation time at start of step [in] dt_lev baroclinic time step at level [in] iteration iteration in subcycling, if using [in] ncycle total number of subcycles, if using
Definition at line 17 of file REMORA_Advance.cpp.
Referenced by timeStep().

◆ advance_2d()
| void REMORA::advance_2d | ( | int | lev, |
| amrex::MultiFab const * | mf_rhoS, | ||
| amrex::MultiFab const * | mf_rhoA, | ||
| amrex::MultiFab * | mf_ru2d, | ||
| amrex::MultiFab * | mf_rv2d, | ||
| amrex::MultiFab * | mf_rufrc, | ||
| amrex::MultiFab * | mf_rvfrc, | ||
| amrex::MultiFab * | mf_Zt_avg1, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_DU_avg1, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_DU_avg2, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_DV_avg1, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_DV_avg2, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_rubar, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_rvbar, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_rzeta, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_ubar, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_vbar, | ||
| amrex::MultiFab * | mf_zeta, | ||
| amrex::MultiFab const * | mf_h, | ||
| amrex::MultiFab const * | mf_pm, | ||
| amrex::MultiFab const * | mf_pn, | ||
| amrex::MultiFab const * | mf_fcor, | ||
| amrex::MultiFab const * | mf_visc2_p, | ||
| amrex::MultiFab const * | mf_visc2_r, | ||
| amrex::MultiFab const * | mf_mskr, | ||
| amrex::MultiFab const * | mf_msku, | ||
| amrex::MultiFab const * | mf_mskv, | ||
| amrex::MultiFab const * | mf_mskp, | ||
| amrex::Real | dtfast_lev, | ||
| bool | predictor_2d_step, | ||
| bool | first_2d_step, | ||
| int | my_iif, | ||
| int & | next_indx1 | ||
| ) |
Perform a 2D predictor (predictor_2d_step=True) or corrector (predictor_2d_step=False) step.
Nonlinear shallow-water rpimitive equations predictor (Leap-frog) and corrector (Adams-Moulton) time-stepping engine. Corresponds to Nonlinear/step2d_LF_AM3.h in ROMS.
- Parameters
-
[in] lev level of refinement (coarsest level is 0) [in] mf_rhoS density perturbation [in] mf_rhoA vertically-averaged density [in,out] mf_ru2d RHS contributions to 2D u-momentum [in,out] mf_rv2d RHS contribtuions to 2D v-momentum [in,out] mf_rufrc before first predictor, vertical integral of 3D RHS for uvel, converted to forcing terms [in,out] mf_rvfrc before first predictor, vertical integral of 3D RHS for vvel, converted to forcing term [in,out] mf_Zt_avg1 average of sea surface height over all fast steps [in,out] mf_DU_avg1 time-averaged u-flux for 2D equations [in,out] mf_DU_avg2 time-averaged u-flux for 3D equation coupling [in,out] mf_DV_avg1 time-averaged v-flux for 2D equations [in,out] mf_DV_avg2 time-averaged v-flux for 3D equation coupling [in,out] mf_rubar RHS of vertically integrated u-momentum [in,out] mf_rvbar RHS of vertically integrated v-momentum [in,out] mf_rzeta RHS of sea surface height [in,out] mf_ubar vertically integrated u-momentum [in,out] mf_vbar vertically integrated v-momentum [in,out] mf_zeta Sea-surface height [in] mf_h Bathymetry [in] mf_pm 1 / dx [in] mf_pn 1 / dy [in] mf_fcor Coriolis factor [in,out] mf_visc2_p Harmonic viscosity at psi points [in,out] mf_visc2_r Harmoic viscosity at rho points [in] mf_mskr Land-sea mask at rho-points [in] mf_msku Land-sea mask at u-points [in] mf_mskv Land-sea mask at v-points [in] mf_mskp Land-sea mask at psi-points [in] dtfast_lev Length of current barotropic step [in] predictor_2d_step Is this a predictor step? [in] first_2d_step Is this the first barotropic step? [in] my_iif Which barotropic predictor-corrector pair? [in,out] next_indx1 Cached index for
Definition at line 44 of file REMORA_advance_2d.cpp.
Referenced by advance_2d_onestep().

◆ advance_2d_onestep()
| void REMORA::advance_2d_onestep | ( | int | lev, |
| amrex::Real | dt_lev, | ||
| amrex::Real | dtfast_lev, | ||
| int | my_iif, | ||
| int | nfast_counter | ||
| ) |
2D advance, one predictor/corrector step
- Parameters
-
[in] lev level of refinement [in] dt_lev baroclinic time step at level [in] dtfast_lev barotropic time step at level [in] my_iif current barotropic time step [in] nfast_counter how many bartropicc time steps to do per baroclinic step
Definition at line 12 of file REMORA_advance_2d_onestep.cpp.
Referenced by Advance(), and timeStepML().
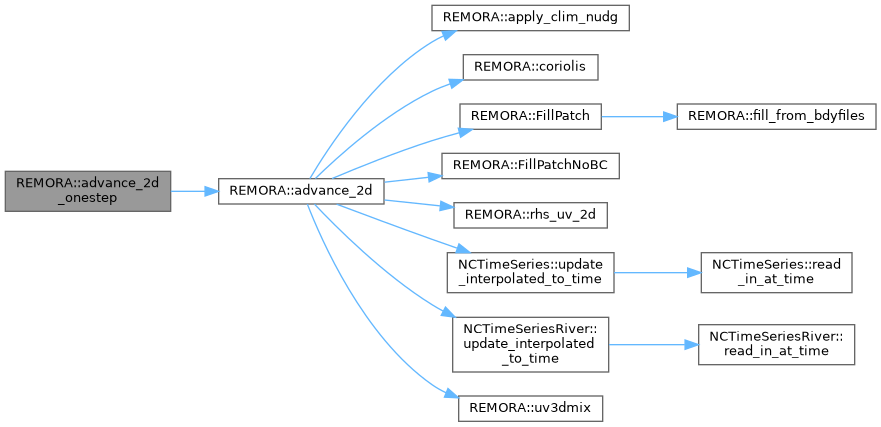

◆ advance_3d()
| void REMORA::advance_3d | ( | int | lev, |
| amrex::MultiFab & | mf_cons, | ||
| amrex::MultiFab & | mf_u, | ||
| amrex::MultiFab & | mf_v, | ||
| amrex::MultiFab * | mf_sstore, | ||
| amrex::MultiFab * | mf_ru, | ||
| amrex::MultiFab * | mf_rv, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_DU_avg1, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_DU_avg2, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_DV_avg1, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_DV_avg2, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_ubar, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_vbar, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_Akv, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_Akt, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_Hz, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_Huon, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_Hvom, | ||
| std::unique_ptr< amrex::MultiFab > & | mf_z_w, | ||
| amrex::MultiFab const * | mf_h, | ||
| amrex::MultiFab const * | mf_pm, | ||
| amrex::MultiFab const * | mf_pn, | ||
| amrex::MultiFab const * | mf_mskr, | ||
| amrex::MultiFab const * | mf_msku, | ||
| amrex::MultiFab const * | mf_mskv, | ||
| const int | N, | ||
| const amrex::Real | dt_lev | ||
| ) |
Advance the 3D variables.
Corresponds to step3d_uv.F and step3d_t.F in ROMS
- Parameters
-
[in] lev level of refinement (coarsest level is 0) [in,out] mf_cons scalar variables (temp, salt, scalar, etc) [in,out] mf_u u-velocity [in,out] mf_v v-velocity [in,out] mf_sstore intermediate-step scalar variables [in,out] mf_ru RHS of total u-velocity [in,out] mf_rv RHS of total v-velocity [in] mf_DU_avg1 time-averaged u-flux for 2D equations [in] mf_DU_avg2 time-averaged u-flux for 3D equation coupling [in] mf_DV_avg1 time-averaged v-flux for 2D equations [in] mf_DV_avg2 time-averaged v-flux for 3D equation coupling [in,out] mf_ubar vertically integrated u-momentum [in,out] mf_vbar vertically integrated v-momentum [in,out] mf_Akv vertical viscosity coefficient [in,out] mf_Akt vertical diffusivity coefficient [in,out] mf_Hz vertical height of cells [in,out] mf_Huon u-volume flux [in,out] mf_Huon v-volume flux [in,out] mf_z_w vertical coordinates on w points [in] mf_h bathymetry [in] mf_pm 1 / dx [in] mf_pn 1 / dy [in] mf_msku land-sea mask at u-points [in] mf_mskv land-sea mask at v-points [in] N number of vertical levels [in] dt_lev time step at this refinement level
Definition at line 35 of file REMORA_advance_3d.cpp.
Referenced by advance_3d_ml().
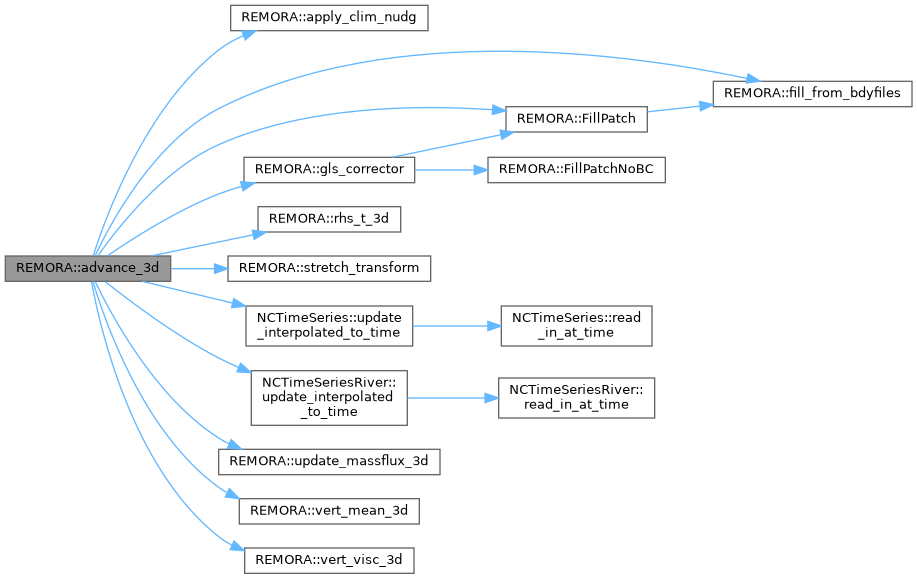

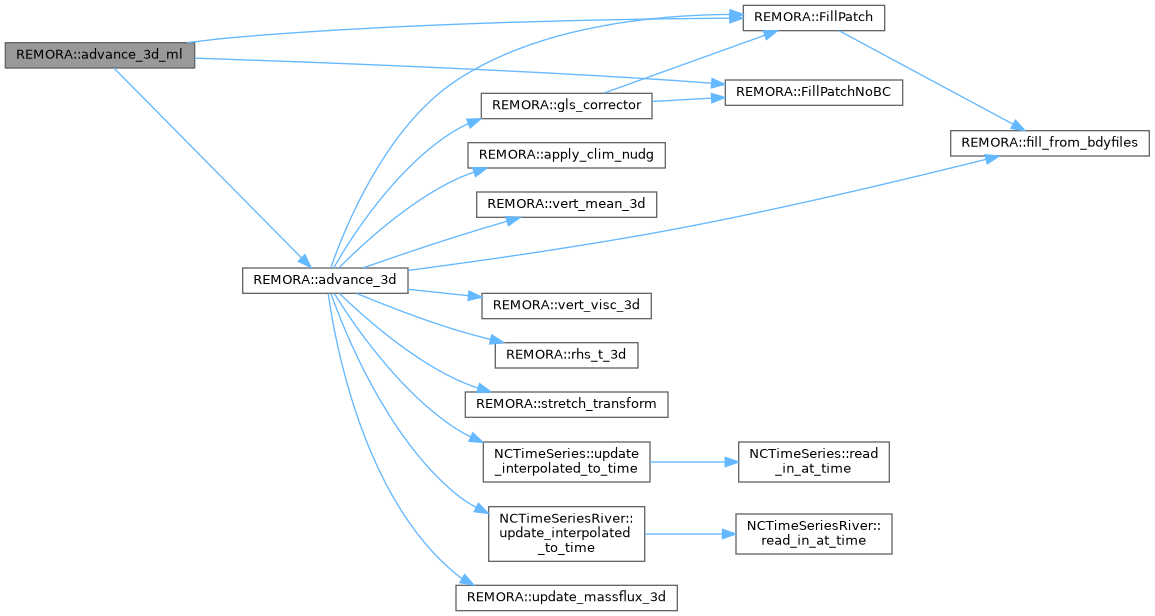
◆ advance_3d_ml()
| void REMORA::advance_3d_ml | ( | int | lev, |
| amrex::Real | dt_lev | ||
| ) |
3D advance on a single level
- Parameters
-
[in] lev refinement level [in] dt_lev time step at refinement level
Definition at line 9 of file REMORA_advance_3d_ml.cpp.
Referenced by Advance(), and timeStepML().

◆ allocate_bathymetry_grid_vars_full_domain()
| void REMORA::allocate_bathymetry_grid_vars_full_domain | ( | ) |
Allocate multifabs for storing full-domain bathymetry and grid vars data.
Definition at line 218 of file REMORA_init.cpp.
Referenced by init_only().

◆ allocate_init_full_domain()
| void REMORA::allocate_init_full_domain | ( | ) |
Allocate multifabs for storing full-domain high resolution initial data.
Definition at line 257 of file REMORA_init.cpp.
Referenced by init_only().

◆ append2DPlotVariables()
|
private |
- Parameters
-
pp_plot_var_names_2d variables to add to plot list
Definition at line 240 of file REMORA_SetPlotVars.cpp.
Referenced by InitData().


◆ append3DPlotVariables()
|
private |
- Parameters
-
pp_plot_var_names variables to add to plot list
Definition at line 198 of file REMORA_SetPlotVars.cpp.
Referenced by InitData().


◆ apply_clim_nudg()
| void REMORA::apply_clim_nudg | ( | const amrex::Box & | bx, |
| int | ioff, | ||
| int | joff, | ||
| const amrex::Array4< amrex::Real > & | var, | ||
| const amrex::Array4< amrex::Real const > & | var_old, | ||
| const amrex::Array4< amrex::Real const > & | var_clim, | ||
| const amrex::Array4< amrex::Real const > & | clim_coeff, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | pm, | ||
| const amrex::Array4< amrex::Real const > & | pn, | ||
| const amrex::Real | dt_lev = amrex::Real(0.0) |
||
| ) |
Apply climatology nudging.
- Parameters
-
[in] bx box to apply climatology on [in] ioff offset in x-direction [in] joff offset in y-direction [in,out] var variable to update [in] var_old variable to compare against for nudging [in] var_clim climatology value to nudge towards [in] clim_coeff nudging time scale (1/s) [in] Hz vertical cell height [in] pm 1/dx [in] pn 1/dy [in] dt_lev time step
Definition at line 19 of file REMORA_apply_clim_nudg.cpp.
Referenced by advance_2d(), advance_3d(), and setup_step().

◆ ApplyAtmosphericStates()
| void REMORA::ApplyAtmosphericStates | ( | const amrex::Vector< amrex::MultiFab * > & | states, |
| amrex::Real | time | ||
| ) |
Receives atmospheric states from the driver and applies unit conversions.
Fills REMORA's internal forcing MultiFabs from states and records which lanes were successfully updated in driver_atmos_state_from_driver. Unit conversions applied: Pair Pa to mb; Tair K to Celsius.
- Parameters
-
[in] states ATM2OCN forcing slab buffer from the driver (Warner et al. 2010, Block B state-passing contract), indexed by AtmosState. Expected units per lane: Uwind/Vwind: 10-m winds [m/s]; Pair: mean sea-level pressure [Pa, converted to mb]; Qair: near-surface specific humidity [kg/kg]; Tair: 2-m air temperature [K, converted to degC]; Cloud: cloud fraction [0-1]; Rain: precipitation rate [kg/m^2/s]; SWrad/LWrad: downwelling shortwave/longwave radiation [W/m^2]. Missing lanes (null pointer or index out of range) are skipped; driver_atmos_state_from_driver tracks populated lanes for the bulk-flux parameterization fallback logic. [in] time Current ocean model time (unused; retained for driver interface conformance).
Definition at line 207 of file REMORA_Coupling.cpp.
◆ average_down_with_grow_cells()
| void REMORA::average_down_with_grow_cells | ( | int | lev, |
| amrex::Vector< std::unique_ptr< amrex::MultiFab > > & | mf | ||
| ) |
Average down from level lev+1 to lev in mf, including grow cells.
- Parameters
-
[in] crse_lev level to average data down to [in,out] vec_mf vector over levels of multifabs containing data to average
Definition at line 1850 of file REMORA.cpp.
Referenced by init_bathymetry_full_domain_from_analytic(), init_bathymetry_full_domain_from_netcdf(), init_data_full_domain_from_netcdf(), init_full_domain_from_analytic(), init_full_domain_zeta_from_analytic(), init_grid_vars_full_domain_from_netcdf(), and init_zeta_full_domain_from_netcdf().

◆ AverageDown()
|
private |
set covered coarse cells to be the average of overlying fine cells
Definition at line 1809 of file REMORA.cpp.
Referenced by InitData().


◆ AverageDownTo()
|
private |
more flexible version of AverageDown() that lets you average down across multiple levels
- Parameters
-
[in] crse_lev level to average down to
Definition at line 1822 of file REMORA.cpp.
Referenced by AverageDown(), post_timestep(), timeStep(), and timeStepML().


◆ build_fine_mask()
| MultiFab & REMORA::build_fine_mask | ( | int | level | ) |
Make mask to zero out covered cells (for mesh refinement)
- Parameters
-
[in] lev level to calculate on
Definition at line 162 of file REMORA_SumIQ.cpp.
Referenced by volWgtSumMF().

◆ bulk_fluxes()
| void REMORA::bulk_fluxes | ( | int | lev, |
| amrex::MultiFab * | mf_cons, | ||
| amrex::MultiFab * | mf_uwind, | ||
| amrex::MultiFab * | mf_vwind, | ||
| amrex::MultiFab * | mf_Tair, | ||
| amrex::MultiFab * | mf_qair, | ||
| amrex::MultiFab * | mf_Pair, | ||
| amrex::MultiFab * | mf_srflx, | ||
| amrex::MultiFab * | mf_longwave_down, | ||
| amrex::MultiFab * | mf_evap, | ||
| amrex::MultiFab * | mf_sustr, | ||
| amrex::MultiFab * | mf_svstr, | ||
| amrex::MultiFab * | mf_stflux, | ||
| amrex::MultiFab * | mf_lrflx, | ||
| amrex::MultiFab * | mf_lhflx, | ||
| amrex::MultiFab * | mf_shflx, | ||
| const int | N | ||
| ) |
Calculate bulk temperature, salinity, wind fluxes.
- Parameters
-
[in] lev level to operate on [in] mf_cons scalar data: temperature, salinity, passsive scalar, etc [in] mf_uwind u-direction wind dvelocity [in] mf_vwind v-direction wind dvelocity [in] mf_Tair air temperature [°C] [in] mf_qair specific humidity [kg/kg] [in] mf_Pair air pressure [mb] [in] mf_srflx shortwave radiation flux [W/m²] [in] mf_longwave_down longwave radiation flux [W/m²] [in,out] mf_evap evaporation rate [out] mf_sustr u-direction surface momentum stress [out] mf_svstr v-direction surface momentum stress [out] mf_stflux surface scalar flux (temperature, salinity) [out] mf_lrflx longwave radiation flux [in,out] mf_lhflx latent heat flux [in,out] mf_shflx sensible heat flux [in] N number of vertical levels
Spec Hum (kg/kg)
Definition at line 25 of file REMORA_bulk_flux.cpp.
Referenced by nonlin_eos(), and setup_step().

◆ bulk_psit()
|
inlinestatic |
Evaluate stability function psi for moisture and heat.
Definition at line 1777 of file REMORA.H.
Referenced by bulk_fluxes().

◆ bulk_psiu()
|
inlinestatic |
Evaluate stability function psi for wind speed.
Definition at line 1745 of file REMORA.H.
Referenced by bulk_fluxes().

◆ calc_stretch_coeffs()
| void REMORA::calc_stretch_coeffs | ( | ) |
calculate vertical stretch coefficients
Definition at line 12 of file REMORA_DepthStretchTransform.H.
Referenced by init_stretch_coeffs().

◆ calculate_nodal_masks()
| void REMORA::calculate_nodal_masks | ( | int | lev | ) |
Calculate u-, v-, and psi-point masks based on rho-point masks after analytic initialization.
- Parameters
-
[in] lev level to operate on
Definition at line 985 of file REMORA_make_new_level.cpp.
Referenced by MakeNewLevelFromCoarse(), RemakeLevel(), and set_masks().

◆ ClearLevel()
|
overridevirtual |
Delete level data Overrides the pure virtual function in AmrCore.
Delete level data. Overrides the pure virtual function in AmrCore
- Parameters
-
[in] lev level to operate on
Definition at line 759 of file REMORA_make_new_level.cpp.
◆ ComputeDt()
|
private |
a wrapper for estTimeStep()
Definition at line 6 of file REMORA_ComputeTimestep.cpp.
Referenced by Evolve(), EvolveOneStep(), and InitData().


◆ ComputeGhostCells()
|
inlineprivate |
Helper function to determine number of ghost cells.
Definition at line 1648 of file REMORA.H.
Referenced by MakeNewLevelFromScratch(), and RemakeLevel().

◆ Construct_REMORAFillPatchers()
|
private |
Construct FillPatchers.
- Parameters
-
[in] lev level to operate on
Definition at line 481 of file REMORA.cpp.
Referenced by init_stuff(), InitData(), and MakeNewLevelFromCoarse().

◆ convert_inv_days_to_inv_s()
| void REMORA::convert_inv_days_to_inv_s | ( | amrex::MultiFab * | ) |
Convert data in a multifab from inverse days to inverse seconds.
- Parameters
-
[in,out] mf multifab of data to convert
Definition at line 727 of file REMORA_init_from_netcdf.cpp.
Referenced by init_clim_nudg_coeff_from_netcdf().

◆ coriolis()
| void REMORA::coriolis | ( | const amrex::Box & | xbx, |
| const amrex::Box & | ybx, | ||
| const amrex::Array4< amrex::Real const > & | uold, | ||
| const amrex::Array4< amrex::Real const > & | vold, | ||
| const amrex::Array4< amrex::Real > & | ru, | ||
| const amrex::Array4< amrex::Real > & | rv, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | fomn, | ||
| int | nrhs, | ||
| int | nr | ||
| ) |
Calculate Coriolis terms.
- Parameters
-
[in] xbx nodal box in x-direction [in] ybx nodal box in y-direction [in] uold u-direction velocity [in] vold v-direction velocity [in,out] ru u-direction velocity RHS [in,out] rv v-direction velocity RHS [in] Hz vertical cell height [in] fomn scaled coriolis factor [in] nrhs which velocity component to use [in] nr which RHS component to update
Definition at line 19 of file REMORA_coriolis.cpp.
Referenced by advance_2d(), and setup_step().

◆ curvilinear()
| void REMORA::curvilinear | ( | const amrex::Box & | bx, |
| const amrex::Box & | xbx, | ||
| const amrex::Box & | ybx, | ||
| const amrex::Array4< amrex::Real const > & | uold, | ||
| const amrex::Array4< amrex::Real const > & | vold, | ||
| const amrex::Array4< amrex::Real > & | ru, | ||
| const amrex::Array4< amrex::Real > & | rv, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | dndx, | ||
| const amrex::Array4< amrex::Real const > & | dmde, | ||
| int | nrhs, | ||
| int | nr | ||
| ) |
Calculate curvilinear advection terms.
- Parameters
-
[in] bx box to update on [in] xbx nodal-x box to update on [in] ybx nodal-y box to update on [in] uold u-direction velocity [in] vold v-direction velocity [in,out] ru u-direction velocity RHS [in,out] rv v-direction velocity RHS [in] Hz vertical cell height [in] dndx d(1/n)/d(xi) [in] dmde d(1/m)/d(eta) [in] nrhs which velocity component to use [in] nr which RHS component to update
Definition at line 21 of file REMORA_curvilinear.cpp.
Referenced by advance_2d(), and setup_step().

◆ DataLog()
|
inlineprivate |
Helper function for IO stream.
Definition at line 1676 of file REMORA.H.
Referenced by sum_integrated_quantities().

◆ DataLogName()
|
inlineprivatenoexcept |
◆ Define_REMORAFillPatchers()
|
private |
Define FillPatchers.
- Parameters
-
[in] lev level to operate on
Definition at line 530 of file REMORA.cpp.
Referenced by init_stuff(), MakeNewLevelFromCoarse(), and RemakeLevel().

◆ ErrorEst()
|
overridevirtual |
Tag cells for refinement.
Function to tag cells for refinement – this overrides the pure virtual function in AmrCore
- Parameters
-
[in] levc level of refinement (0 is coarsest level) [out] tags array of tagged cells [in] time current time [in] ngrow number of grow cells
Definition at line 15 of file REMORA_Tagging.cpp.
◆ estTimeStep()
| Real REMORA::estTimeStep | ( | int | level | ) | const |
compute dt from CFL considerations
- Parameters
-
[in] level level of refinement
Definition at line 41 of file REMORA_ComputeTimestep.cpp.
Referenced by ComputeDt().

◆ Evolve()
| void REMORA::Evolve | ( | ) |
Advance solution to final time.
Definition at line 247 of file REMORA.cpp.
Referenced by main().

◆ EvolveOneStep()
| amrex::Real REMORA::EvolveOneStep | ( | amrex::Real | time, |
| amrex::Real | dt_request | ||
| ) |

◆ extrapolate_metric_to_physical_boundaries()
| void REMORA::extrapolate_metric_to_physical_boundaries | ( | amrex::MultiFab & | mf, |
| const amrex::Geometry & | geom | ||
| ) |
Extrapolate grid metrics to edge of MultiFab.
- Parameters
-
[in,out] mf multifab of data to extrapolate on [in] geom geometry
Definition at line 821 of file REMORA_init_from_netcdf.cpp.
Referenced by init_grid_vars_from_netcdf(), and init_grid_vars_full_domain_from_netcdf().

◆ fill_3d_masks()
| void REMORA::fill_3d_masks | ( | int | lev | ) |
Copy maskr to all z levels.
- Parameters
-
[in] lev level to operate on
Definition at line 1009 of file REMORA_make_new_level.cpp.
Referenced by set_masks().

◆ fill_from_bdyfiles()
| void REMORA::fill_from_bdyfiles | ( | int | lev, |
| amrex::MultiFab & | mf_to_fill, | ||
| const amrex::MultiFab & | mf_mask, | ||
| const amrex::Real | time, | ||
| const int | bccomp, | ||
| const int | bdy_var_type, | ||
| const int | icomp_to_fill, | ||
| const int | icomp_calc = 0, |
||
| const amrex::MultiFab & | mf_calc = amrex::MultiFab(), |
||
| const amrex::Real | = amrex::Real(0.0) |
||
| ) |
Fill boundary data from netcdf file.
Definition at line 20 of file REMORA_BoundaryConditions_netcdf.cpp.
Referenced by advance_3d(), FillCoarsePatchMap(), FillPatch(), and init_zeta_from_netcdf().
◆ FillBdyCCVels()
| void REMORA::FillBdyCCVels | ( | int | lev, |
| amrex::MultiFab & | mf_cc_vel | ||
| ) |
Fill the physical boundary conditions for cell-centered velocity (diagnostic only)
- Parameters
-
[in] lev level to fill at [in] lev MultiFab of cell-centered velocities
Definition at line 601 of file REMORA_FillPatch.cpp.
Referenced by ErrorEst().


◆ FillCoarsePatch()
| void REMORA::FillCoarsePatch | ( | int | lev, |
| amrex::Real | time, | ||
| amrex::MultiFab * | mf_fine, | ||
| amrex::MultiFab * | mf_crse, | ||
| const int | bccomp, | ||
| const int | bdy_var_type = BdyVars::null, |
||
| const int | icomp = 0, |
||
| const bool | fill_all = true, |
||
| const int | n_not_fill = 0, |
||
| const int | icomp_calc = 0, |
||
| const amrex::Real | dt = amrex::Real(0.0), |
||
| const amrex::MultiFab & | mf_calc = amrex::MultiFab() |
||
| ) |
fill an entire multifab by interpolating from the coarser level
Fill an entire multifab by interpolating from the coarser level – this is used only when a new level of refinement is being created during a run (i.e not at initialization) This will never be used with static refinement.
- Parameters
-
[in] lev level to FillPatch on [in] time current time [in,out] mf_to_fill MultiFab to fill [in,out] mf_crse MultiFab of coarse data [in] bccomp index into domain_bcs_type [in] bdy_var_type when filling from NetCDF, which boundary data [in] icomp component to fill [in] fill_all whether to fill all components [in] icomp_calc component to use in RHS boundary calculation [in] dt_lev time step at this level [in] mf_calc data to use in RHS boundary calculation
Definition at line 411 of file REMORA_FillPatch.cpp.
Referenced by FillCoarsePatchMap(), init_only(), MakeNewLevelFromCoarse(), set_bathymetry(), set_coriolis(), set_grid_scale(), and set_zeta().

◆ FillCoarsePatchMap()
| void REMORA::FillCoarsePatchMap | ( | int | lev, |
| amrex::Real | time, | ||
| amrex::MultiFab * | mf_fine, | ||
| amrex::MultiFab * | mf_crse, | ||
| const int | bccomp, | ||
| const int | bdy_var_type = BdyVars::null, |
||
| const int | icomp = 0, |
||
| const bool | fill_all = true, |
||
| const int | n_not_fill = 0, |
||
| const int | icomp_calc = 0, |
||
| const amrex::Real | dt = amrex::Real(0.0), |
||
| const amrex::MultiFab & | mf_calc = amrex::MultiFab(), |
||
| amrex::Interpolater * | mapper = nullptr |
||
| ) |
fill an entire multifab by interpolating from the coarser level, explicitly specifying interpolator to use
Fill an entire multifab by interpolating from the coarser level – this is used only when a new level of refinement is being created during a run (i.e not at initialization) This will never be used with static refinement.
- Parameters
-
[in] lev level to FillPatch on [in] time current time [in,out] mf_to_fill MultiFab to fill [in,out] mf_crse MultiFab of coarse data [in] bccomp index into domain_bcs_type [in] bdy_var_type when filling from NetCDF, which boundary data [in] icomp component to fill [in] fill_all whether to fill all components [in] icomp_calc component to use in RHS boundary calculation [in] dt_lev time step at this level [in] mf_calc data to use in RHS boundary calculation
Definition at line 445 of file REMORA_FillPatch.cpp.
Referenced by FillCoarsePatch(), and FillCoarsePatchPC().

◆ FillCoarsePatchPC()
| void REMORA::FillCoarsePatchPC | ( | int | lev, |
| amrex::Real | time, | ||
| amrex::MultiFab * | mf_fine, | ||
| amrex::MultiFab * | mf_crse, | ||
| const int | bccomp, | ||
| const int | bdy_var_type = BdyVars::null, |
||
| const int | icomp = 0, |
||
| const bool | fill_all = true, |
||
| const int | n_not_fill = 0, |
||
| const int | icomp_calc = 0, |
||
| const amrex::Real | dt = amrex::Real(0.0), |
||
| const amrex::MultiFab & | mf_calc = amrex::MultiFab() |
||
| ) |
fill an entire multifab by interpolating from the coarser level using the piecewise constant interpolater
Like FillCoarsePatch but uses piecewise constant interpolater
- Parameters
-
[in] lev level to FillPatch on [in] time current time [in,out] mf_to_fill MultiFab to fill [in,out] mf_crse MultiFab of coarse data [in] bccomp index into domain_bcs_type [in] bdy_var_type when filling from NetCDF, which boundary data [in] icomp component to fill [in] fill_all whether to fill all components [in] icomp_calc component to use in RHS boundary calculation [in] dt_lev time step at this level [in] mf_calc data to use in RHS boundary calculation
Definition at line 377 of file REMORA_FillPatch.cpp.
Referenced by MakeNewLevelFromCoarse(), RemakeLevel(), and set_masks().
◆ FillPatch()
| void REMORA::FillPatch | ( | int | lev, |
| amrex::Real | time, | ||
| amrex::MultiFab & | mf_to_be_filled, | ||
| amrex::Vector< amrex::MultiFab * > const & | mfs, | ||
| const int | bccomp, | ||
| const int | bdy_var_type = BdyVars::null, |
||
| const int | icomp = 0, |
||
| const bool | fill_all = true, |
||
| const bool | fill_set = true, |
||
| const int | n_not_fill = 0, |
||
| const int | icomp_calc = 0, |
||
| const amrex::Real | dt = amrex::Real(0.0), |
||
| const amrex::MultiFab & | mf_calc = amrex::MultiFab() |
||
| ) |
Fill a new MultiFab by copying in phi from valid region and filling ghost cells.
Fill valid and ghost data in the MultiFab "mf" This version fills the MultiFab mf_to_fill in valid regions with the "state data" at the given time; values in mf when it is passed in are not used.
- Parameters
-
[in] lev level to FillPatch on [in] time current time [in,out] mf_to_fill MultiFab to fill [in] mfs vector over levels of multifabs associated with mf_to_fill [in] bccomp index into domain_bcs_type [in] bdy_var_type when filling from NetCDF, which boundary data [in] icomp component to fill [in] fill_all whether to fill all components [in] fill_set whether to use FillPatchers [in] icomp_calc component to use in RHS boundary calculation [in] dt_lev time step at this level [in] mf_calc data to use in RHS boundary calculation
Definition at line 30 of file REMORA_FillPatch.cpp.
Referenced by advance_2d(), advance_3d(), advance_3d_ml(), ErrorEst(), gls_corrector(), gls_prestep(), init_bathymetry_from_netcdf(), init_grid_vars_from_netcdf(), init_zeta_from_netcdf(), InitData(), RemakeLevel(), set_2darrays(), set_analytic_vmix(), set_bathymetry_averaged_down(), set_coriolis(), set_grid_vars_averaged_down(), set_hmixcoef(), set_init_data_averaged_down(), set_smflux(), set_wind(), set_zeta_averaged_down(), setup_step(), and timeStepML().

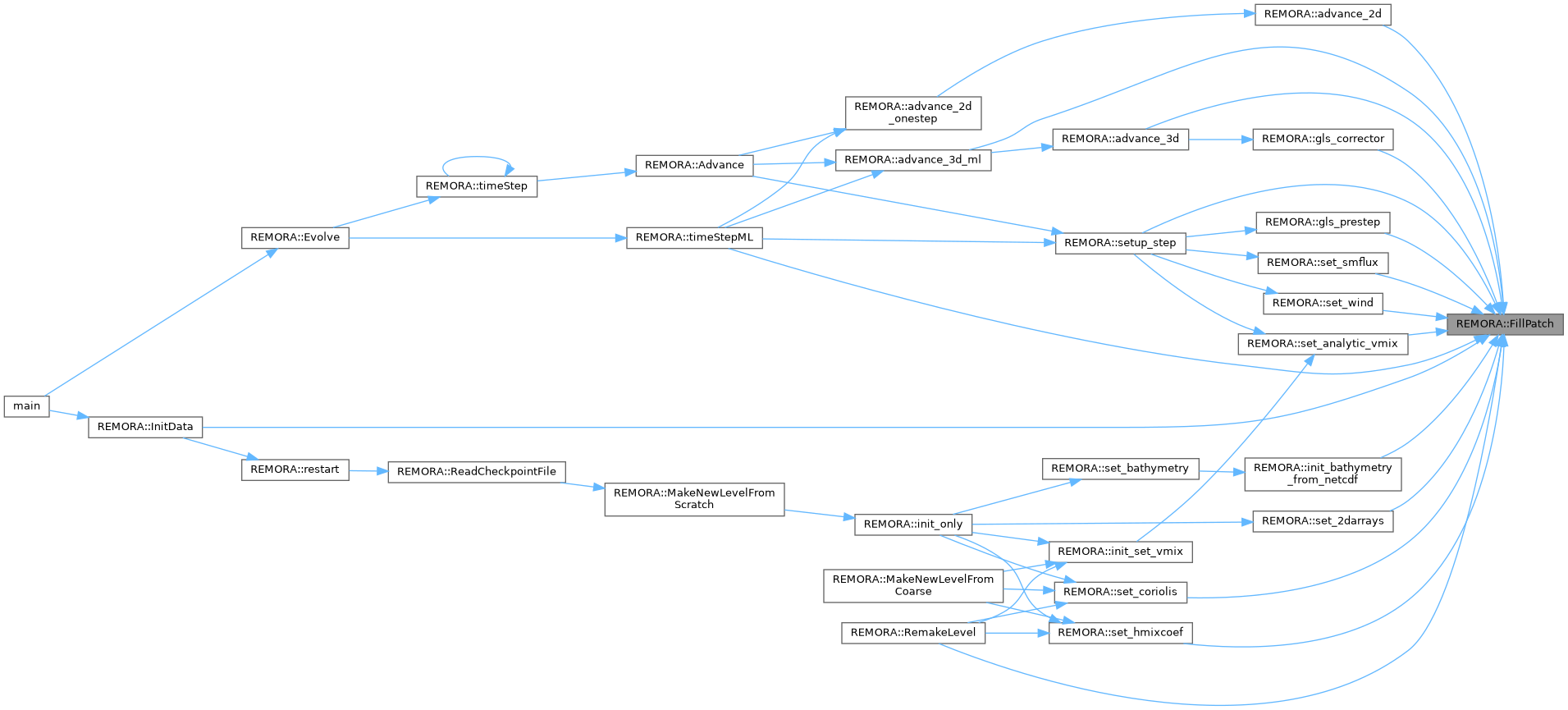
◆ FillPatchNoBC()
| void REMORA::FillPatchNoBC | ( | int | lev, |
| amrex::Real | time, | ||
| amrex::MultiFab & | mf_to_be_filled, | ||
| amrex::Vector< amrex::MultiFab * > const & | mfs, | ||
| const int | bdy_var_type = BdyVars::null, |
||
| const int | icomp = 0, |
||
| const bool | fill_all = true, |
||
| const bool | fill_set = true |
||
| ) |
Fill a new MultiFab by copying in phi from valid region and filling ghost cells without applying boundary conditions.
Fill valid and ghost data in the MultiFab "mf" This version fills the MultiFab mf_to_fill in valid regions with the "state data" at the given time; values in mf when it is passed in are not used. Unlike FillPatch, FillPatchNoBC does not apply boundary conditions
- Parameters
-
[in] lev level to FillPatch on [in] time current time [in,out] mf_to_fill MultiFab to fill [in] mfs vector over levels of multifabs associated with mf_to_fill [in] bdy_var_type when filling from NetCDF, which boundary data [in] icomp component to fill [in] fill_all whether to fill all components [in] fill_set whether to use FillPatchers
Definition at line 199 of file REMORA_FillPatch.cpp.
Referenced by advance_2d(), advance_3d_ml(), gls_corrector(), setup_step(), timeStepML(), and WritePlotFile().


◆ foextrap_bc()
|
inlinenoexcept |
Definition at line 1177 of file REMORA.H.
Referenced by gls_corrector(), init_bcs(), init_only(), MakeNewLevelFromCoarse(), RemakeLevel(), set_coriolis(), set_grid_scale(), set_masks(), and WritePlotFile().

◆ foextrap_periodic_bc()
|
inlinenoexcept |
Definition at line 1176 of file REMORA.H.
Referenced by init_bathymetry_from_netcdf(), init_bcs(), init_grid_vars_from_netcdf(), set_bathymetry_averaged_down(), set_grid_vars_averaged_down(), set_hmixcoef(), set_smflux(), and set_wind().


◆ get_t_old()
| amrex::Real REMORA::get_t_old | ( | int | lev | ) | const |
Accessor method for t_old to expose to outside classes.
- Parameters
-
[in] lev level at which to get time
Definition at line 1884 of file REMORA.cpp.
◆ getCPUTime()
|
inlineprivate |
Get CPU time used.
Definition at line 1695 of file REMORA.H.
Referenced by writeJobInfo().

◆ GetDataAtTime()
|
private |
utility to copy in data from old and/or new state into another multifab
Definition at line 303 of file REMORA_FillPatch.cpp.
Referenced by FillCoarsePatchMap(), and GetDataAtTime().
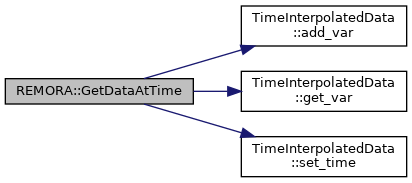

◆ gls_corrector()
| void REMORA::gls_corrector | ( | int | lev, |
| amrex::MultiFab * | mf_gls, | ||
| amrex::MultiFab * | mf_tke, | ||
| amrex::MultiFab & | mf_W, | ||
| amrex::MultiFab * | mf_Akv, | ||
| amrex::MultiFab * | mf_Akt, | ||
| amrex::MultiFab * | mf_Akk, | ||
| amrex::MultiFab * | mf_Akp, | ||
| amrex::MultiFab * | mf_mskr, | ||
| amrex::MultiFab * | mf_msku, | ||
| amrex::MultiFab * | mf_mskv, | ||
| const int | nstp, | ||
| const int | nnew, | ||
| const int | N, | ||
| const amrex::Real | dt_lev | ||
| ) |
Corrector step for GLS calculation.
- Parameters
-
[in] lev level to operate on [in,out] mf_gls turbulent generic length scale [in,out] mf_tke turbulent kinetic energy [in] mf_W vertical velocity [in,out] mf_Akv vertical viscosity coefficient [in,out] mf_Akt vertical diffusivity coefficients [in,out] mf_Akk turbulent kinetic energy vertical diffusion coefficient [in,out] mf_Akp turbulent length scale vertical diffusion coefficient [in] mf_mskr land-sea mask on rho points [in] mf_msku land-sea mask on u points [in] mf_mskv land-sea mask on v points [in] nstp index of last time step in gls and tke MultiFabs [in] nnew index of time step to update in gls and tke MultiFabs [in] N number of vertical levels [in] dt_lev time step at this level
Definition at line 247 of file REMORA_gls.cpp.
Referenced by advance_3d().


◆ gls_prestep()
| void REMORA::gls_prestep | ( | int | lev, |
| amrex::MultiFab * | mf_gls, | ||
| amrex::MultiFab * | mf_tke, | ||
| amrex::MultiFab & | mf_W, | ||
| amrex::MultiFab * | mf_msku, | ||
| amrex::MultiFab * | mf_mskv, | ||
| const int | nstp, | ||
| const int | nnew, | ||
| const int | iic, | ||
| const int | ntfirst, | ||
| const int | N, | ||
| const amrex::Real | dt_lev | ||
| ) |
Prestep for GLS calculation.
- Parameters
-
[in] lev level to operate on [in,out] mf_gls turbulent generic length scale [in,out] mf_tke turbulent kinetic energy [in] mf_W vertical velocity [in] mf_msku land-sea mask on u points [in] mf_mskv land-sea mask on v points [in] nstp index of last time step in gls and tke MultiFabs [in] nnew index of time step to update in gls and tke MultiFabs [in] iic which time step we're on [in] ntfirst what is the first time step? [in] N number of vertical levels [in] dt_lev time step at this level
Definition at line 20 of file REMORA_gls.cpp.
Referenced by setup_step().


◆ GotoNextLine()
|
staticprivate |
utility to skip to next line in Header
Definition at line 8 of file REMORA_Checkpoint.cpp.
Referenced by ReadCheckpointFile().

◆ init_analytic()
|
private |
Initialize initial problem data from analytic functions.
- Parameters
-
[in] lev level to initialize on
Definition at line 15 of file REMORA_init.cpp.
Referenced by init_only().


◆ init_bathymetry_from_netcdf()
| void REMORA::init_bathymetry_from_netcdf | ( | int | lev | ) |
Bathymetry data initialization from NetCDF file.
- Parameters
-
lev Integer specifying the current level
Definition at line 402 of file REMORA_init_from_netcdf.cpp.
Referenced by set_bathymetry().


◆ init_bathymetry_full_domain_from_analytic()
| void REMORA::init_bathymetry_full_domain_from_analytic | ( | ) |
Full domain bathymetry data initialization from analytic.
Definition at line 246 of file REMORA_init.cpp.
Referenced by init_only().


◆ init_bathymetry_full_domain_from_netcdf()
| void REMORA::init_bathymetry_full_domain_from_netcdf | ( | ) |
Full domain high-res bathymetry data initialization from NetCDF file.
Definition at line 742 of file REMORA_init_from_netcdf.cpp.
Referenced by init_only().
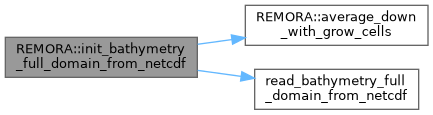

◆ init_bcs()
|
private |
Read in boundary parameters from input file and set up data structures.
Definition at line 9 of file REMORA_init_bcs.cpp.
Referenced by InitData().

◆ init_bdry_from_netcdf()
| void REMORA::init_bdry_from_netcdf | ( | int | lev | ) |
Boundary data initialization from NetCDF file.
- Parameters
-
lev Integer specifying the current level
Definition at line 531 of file REMORA_init_from_netcdf.cpp.
Referenced by init_only().

◆ init_beta_plane_coriolis()
| void REMORA::init_beta_plane_coriolis | ( | int | lev | ) |
Calculate Coriolis parameters from beta plane parametrization.
- Parameters
-
[in] lev level to initialize on
Definition at line 26 of file REMORA_init.cpp.
Referenced by set_coriolis().

◆ init_clim_nudg_coeff()
| void REMORA::init_clim_nudg_coeff | ( | int | lev | ) |
Wrapper to initialize climatology nudging coefficient.
- Parameters
-
[in] lev level to operate on
Definition at line 188 of file REMORA_init.cpp.
Referenced by init_only().


◆ init_clim_nudg_coeff_from_netcdf()
| void REMORA::init_clim_nudg_coeff_from_netcdf | ( | int | lev | ) |
Climatology nudging coefficient initialization from NetCDF file.
- Parameters
-
lev Integer specifying the current level
Definition at line 602 of file REMORA_init_from_netcdf.cpp.
Referenced by init_clim_nudg_coeff().

◆ init_coriolis_from_netcdf()
| void REMORA::init_coriolis_from_netcdf | ( | int | lev | ) |
Coriolis parameter data initialization from NetCDF file.
- Parameters
-
lev Integer specifying the current level
Definition at line 449 of file REMORA_init_from_netcdf.cpp.
Referenced by set_coriolis().


◆ init_data_from_netcdf()
| void REMORA::init_data_from_netcdf | ( | int | lev | ) |
Problem initialization from NetCDF file.
- Parameters
-
lev Integer specifying the current level
Definition at line 112 of file REMORA_init_from_netcdf.cpp.
Referenced by init_only().

◆ init_data_full_domain_from_netcdf()
| void REMORA::init_data_full_domain_from_netcdf | ( | ) |
High resolution roblem initialization from NetCDF file.
Definition at line 157 of file REMORA_init_from_netcdf.cpp.
Referenced by init_only().

◆ init_flat_bathymetry()
| void REMORA::init_flat_bathymetry | ( | int | lev | ) |
Initialize flat bathymetry to value from problo.
- Parameters
-
[in] lev level to operate on
Definition at line 1118 of file REMORA.cpp.
Referenced by set_bathymetry().

◆ init_full_domain_from_analytic()
|
private |
Initialize high resolution initial problem data from analytic functions.
Definition at line 292 of file REMORA_init.cpp.
Referenced by init_only().


◆ init_full_domain_zeta_from_analytic()
|
private |
Initialize high resolution initial sea surface height from analytic functions.
Definition at line 304 of file REMORA_init.cpp.
Referenced by init_only().


◆ init_gls_vmix()
| void REMORA::init_gls_vmix | ( | int | lev, |
| SolverChoice | solver_choice | ||
| ) |
Initialize GLS variables.
- Parameters
-
[in] lev level to operate on [in] solver_choice algorithmic choices
Definition at line 145 of file REMORA_init.cpp.
Referenced by init_set_vmix().

◆ init_grid_vars_from_netcdf()
| void REMORA::init_grid_vars_from_netcdf | ( | int | lev | ) |
Grid variable initialization from NetCDF file.
- Parameters
-
lev Integer specifying the current level
Definition at line 297 of file REMORA_init_from_netcdf.cpp.
Referenced by set_bathymetry(), and set_grid_scale().


◆ init_grid_vars_full_domain_from_netcdf()
| void REMORA::init_grid_vars_full_domain_from_netcdf | ( | ) |
Full domain high-res grid variable initialization from NetCDF file.
Definition at line 765 of file REMORA_init_from_netcdf.cpp.
Referenced by init_only().


◆ init_masks()
|
private |
Allocate MultiFabs for masks.
- Parameters
-
[in] lev level to operate on [in] ba BoxArray for the level [in] dm DistributionMapping for the level
Definition at line 516 of file REMORA_make_new_level.cpp.
Referenced by MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), and RemakeLevel().

◆ init_masks_from_netcdf()
| void REMORA::init_masks_from_netcdf | ( | int | lev | ) |
Mask data initialization from NetCDF file.
- Parameters
-
lev Integer specifying the current level
Definition at line 484 of file REMORA_init_from_netcdf.cpp.
Referenced by set_masks().

◆ init_only()
| void REMORA::init_only | ( | int | lev, |
| amrex::Real | time | ||
| ) |
Init (NOT restart or regrid)
- Parameters
-
[in] lev level to operate on [in] time current time for initialization
Definition at line 1254 of file REMORA.cpp.
Referenced by MakeNewLevelFromScratch().

◆ init_riv_pos_from_netcdf()
| void REMORA::init_riv_pos_from_netcdf | ( | int | lev | ) |
- Parameters
-
[in] lev level to read in river data
Definition at line 678 of file REMORA_init_from_netcdf.cpp.
Referenced by init_only().


◆ init_scalar_metadata()
|
private |
Build runtime scalar names after nscalar is known.
Definition at line 234 of file REMORA.cpp.
Referenced by ReadParameters().

◆ init_set_vmix()
| void REMORA::init_set_vmix | ( | int | lev | ) |
Initialize vertical mixing coefficients from file or analytic.
Definition at line 774 of file REMORA.cpp.
Referenced by init_only(), MakeNewLevelFromCoarse(), and RemakeLevel().


◆ init_stretch_coeffs()
| void REMORA::init_stretch_coeffs | ( | ) |
initialize and calculate stretch coefficients
Definition at line 208 of file REMORA_init.cpp.
Referenced by InitData().


◆ init_stuff()
|
private |
Allocate MultiFabs for state and evolution variables.
- Parameters
-
[in] lev level to operate on [in] ba BoxArray for the level [in] dm DistributionMapping for the level
Definition at line 544 of file REMORA_make_new_level.cpp.
Referenced by MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), and RemakeLevel().

◆ init_zeta_from_netcdf()
| void REMORA::init_zeta_from_netcdf | ( | int | lev | ) |
Sea-surface height data initialization from NetCDF file.
- Parameters
-
lev Integer specifying the current level
Definition at line 211 of file REMORA_init_from_netcdf.cpp.
Referenced by set_zeta().


◆ init_zeta_full_domain_from_netcdf()
| void REMORA::init_zeta_full_domain_from_netcdf | ( | ) |
Full-domain high res sea-surface height data initialization from NetCDF file.
Definition at line 259 of file REMORA_init_from_netcdf.cpp.
Referenced by init_only().

◆ InitData()
| void REMORA::InitData | ( | ) |
Initialize multilevel data.
This is called from main.cpp and handles all initialization, whether from start or restart
Definition at line 376 of file REMORA.cpp.
Referenced by main().

◆ InitializeFromFile()
|
private |
Read the file passed to remora.restart and use it as an initial condition for the current simulation.
◆ InitializeLevelFromData()
|
private |
Initialize the new-time data at a level from the initial_data MultiFab.
◆ is_it_time_for_action()
| bool REMORA::is_it_time_for_action | ( | int | nstep, |
| amrex::Real | time, | ||
| amrex::Real | dt, | ||
| int | action_interval, | ||
| amrex::Real | action_per | ||
| ) |
Decide if it is time to take an action.
- Parameters
-
[in] nstep what step we're on [in] lev level to calculate on [in] dtlev time step for this level [in] action_interval number of time steps between actions [in] action_per time interval between actions
Definition at line 197 of file REMORA_SumIQ.cpp.
Referenced by InitData(), and post_timestep().

◆ lin_eos()
| void REMORA::lin_eos | ( | const amrex::Box & | bx, |
| const amrex::Array4< amrex::Real const > & | state, | ||
| const amrex::Array4< amrex::Real > & | rho, | ||
| const amrex::Array4< amrex::Real > & | rhoA, | ||
| const amrex::Array4< amrex::Real > & | rhoS, | ||
| const amrex::Array4< amrex::Real > & | bvf, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | z_w, | ||
| const amrex::Array4< amrex::Real const > & | z_r, | ||
| const amrex::Array4< amrex::Real const > & | h, | ||
| const amrex::Array4< amrex::Real const > & | mskr, | ||
| const int | N | ||
| ) |
Calculate density and related quantities from linear equation of state.
- Parameters
-
[in] bx box for calculation [in] state state holds temp, salt [out] rho density [out] rhoA vertically-averaged density [out] rhoS density perturbation [out] bvf Brunt-Vaisala frequency [in] Hz vertical cell height [in] z_r z coordinates at rho points [in] z_w z coordinates at w points [in] h bathymetry [in] mskr land-sea mask on rho points [in] N number of vertical levels
Definition at line 61 of file REMORA_rho_eos.cpp.
Referenced by rho_eos().

◆ MakeNewLevelFromCoarse()
|
overridevirtual |
Make a new level using provided BoxArray and DistributionMapping and fill with interpolated coarse level data. Overrides the pure virtual function in AmrCore.
Make a new level using provided BoxArray and DistributionMapping and fill with interpolated coarse level data (overrides the pure virtual function in AmrCore) regrid --> RemakeLevel (if level already existed) regrid --> MakeNewLevelFromCoarse (if adding new level)
- Parameters
-
[in] lev level to make [in] time current time [in] ba BoxArray for the level [in] dm DistributionMapping for the level
Definition at line 24 of file REMORA_make_new_level.cpp.
◆ MakeNewLevelFromScratch()
|
overridevirtual |
Make a new level from scratch using provided BoxArray and DistributionMapping. Only used during initialization. Overrides the pure virtual function in AmrCore.
Make a new level from scratch using provided BoxArray and DistributionMapping. This is called both for initialization and for restart (overrides the pure virtual function in AmrCore) main.cpp --> REMORA::InitData --> InitFromScratch --> MakeNewGrids --> MakeNewLevelFromScratch restart --> MakeNewGrids --> MakeNewLevelFromScratch
- Parameters
-
[in] lev level to make [in] time current time [in] ba BoxArray for the level [in] dm DistributionMapping for the level
Definition at line 326 of file REMORA_make_new_level.cpp.
Referenced by ReadCheckpointFile().

◆ mask_arrays_for_write()
| void REMORA::mask_arrays_for_write | ( | int | lev, |
| amrex::Real | fill_value, | ||
| amrex::Real | fill_where | ||
| ) |
Mask data arrays before writing output.
- Parameters
-
lev level to mask fill_value fill value to mask with fill_where value at cells where we will apply the mask. This is necessary because rivers
Definition at line 939 of file REMORA_Plotfile.cpp.
Referenced by WriteNCPlotFile_which(), and WritePlotFile().

◆ nonlin_eos()
| void REMORA::nonlin_eos | ( | const amrex::Box & | bx, |
| const amrex::Array4< amrex::Real const > & | state, | ||
| const amrex::Array4< amrex::Real > & | rho, | ||
| const amrex::Array4< amrex::Real > & | rhoA, | ||
| const amrex::Array4< amrex::Real > & | rhoS, | ||
| const amrex::Array4< amrex::Real > & | bvf, | ||
| const amrex::Array4< amrex::Real > & | alpha, | ||
| const amrex::Array4< amrex::Real > & | beta, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | z_w, | ||
| const amrex::Array4< amrex::Real const > & | z_r, | ||
| const amrex::Array4< amrex::Real const > & | h, | ||
| const amrex::Array4< amrex::Real const > & | mskr, | ||
| const int | N | ||
| ) |
Calculate density and related quantities from nonlinear equation of state.
- Parameters
-
[in] bx box for calculation [in] state state holds temp, salt [out] rho density [out] rhoA vertically-averaged density [out] rhoS density perturbation [out] bvf Brunt-Vaisala frequency [out] alpha thermal expansion coefficient [out] beta saline contraction coefficient [in] Hz vertical cell height [in] z_r z coordinates at rho points [in] z_w z coordinates at w points [in] h bathymetry [in] mskr land-sea mask on rho points [in] N number of vertical levels
Definition at line 158 of file REMORA_rho_eos.cpp.
Referenced by rho_eos().


◆ num_bc_vars()
|
inlinenoexcept |
Definition at line 1180 of file REMORA.H.
Referenced by init_bcs().


◆ NumDataLogs()
|
inlineprivatenoexcept |
Definition at line 1683 of file REMORA.H.
Referenced by sum_integrated_quantities().

◆ PackSurfaceState()
| void REMORA::PackSurfaceState | ( | amrex::Vector< amrex::MultiFab * > & | state, |
| amrex::Real | time | ||
| ) |
Extracts SST from the 3D conservative state for the atmospheric driver.
Reads Temp_comp at the top water-column cell (k_sfc), converts from Celsius to Kelvin, and copies the result into state[SSTIndex].
- Parameters
-
[in,out] state OCN2ATM slab buffer sized by the driver (one MultiFab per ocean-to-atmosphere export layer). state[SSTIndex] (index 0) is overwritten with sea-surface temperature (SST) sampled from the Temp_comp tracer at the uppermost sigma level (k = Nz) and converted from degrees Celsius to Kelvin for the atmospheric driver. An empty vector or null state[0] is treated as a no-op. [in] time Current ocean model time (unused; retained for driver interface conformance).
Definition at line 105 of file REMORA_Coupling.cpp.
◆ PlotFileName()
|
private |
get plotfile name
◆ post_timestep()
| void REMORA::post_timestep | ( | int | nstep, |
| amrex::Real | time, | ||
| amrex::Real | dt_lev | ||
| ) |
Called after every level 0 timestep.
- Parameters
-
[in] nstep which step we're on [in] time current time [in] dt_lev0 time step on level 0
Definition at line 344 of file REMORA.cpp.
Referenced by Evolve(), and EvolveOneStep().

◆ prestep()
| void REMORA::prestep | ( | int | lev, |
| amrex::MultiFab & | mf_uold, | ||
| amrex::MultiFab & | mf_vold, | ||
| amrex::MultiFab & | mf_u, | ||
| amrex::MultiFab & | mf_v, | ||
| amrex::MultiFab * | mf_ru, | ||
| amrex::MultiFab * | mf_rv, | ||
| amrex::MultiFab & | S_old, | ||
| amrex::MultiFab & | S_new, | ||
| amrex::MultiFab & | mf_W, | ||
| amrex::MultiFab & | mf_DC, | ||
| const amrex::MultiFab * | mf_z_r, | ||
| const amrex::MultiFab * | mf_z_w, | ||
| const amrex::MultiFab * | mf_h, | ||
| const amrex::MultiFab * | mf_pm, | ||
| const amrex::MultiFab * | mf_pn, | ||
| const amrex::MultiFab * | mf_sustr, | ||
| const amrex::MultiFab * | mf_svstr, | ||
| const amrex::MultiFab * | mf_bustr, | ||
| const amrex::MultiFab * | mf_bvstr, | ||
| const amrex::MultiFab * | mf_msku, | ||
| const amrex::MultiFab * | mf_mskv, | ||
| const int | iic, | ||
| const int | nfirst, | ||
| const int | nnew, | ||
| int | nstp, | ||
| int | nrhs, | ||
| int | N, | ||
| const amrex::Real | dt_lev | ||
| ) |
Wrapper function for prestep.
- Parameters
-
[in] lev level to operate on [in] mf_uold u-velocity from last time step [in] mf_vold v-velocity from last time step [out] mf_u u-velocity at current time step [out] mf_v v-velocity at current time step [in,out] mf_ru u-velocity RHS at current time step [in,out] mf_rv v-velocity RHS at current time step [in] S_old scalar variables at last time step [in,out] S_new scalar variables at current time step [in] mf_W vertical velocity mf_DC temporary variable container [in] mf_z_r z coordinates at rho points (cell centers) [in] mf_z_w z coordinates at w points [in] mf_h bathymetry [in] mf_pm 1/dx [in] mf_pn 1/dy [in] mf_sustr u-direction surface momentum flux [in] mf_svstr v-direction surface momentum flux [in] mf_bustr u-direction bottom stress [in] mf_bvstr v-direction bottom stress [in] mf_msku land-sea mask on u-points [in] mf_mskv land-sea mask on v-points [in] iic which time step we're on [in] ntfirst what is the first time step? [in] nnew index of time step to update [in] nstp index of last time step [in] nrhs index of RHS component [in] N number of vertical levels [in] dt_lev time step at this level
Definition at line 38 of file REMORA_prestep.cpp.
Referenced by setup_step().

◆ prestep_diffusion()
| void REMORA::prestep_diffusion | ( | const amrex::Box & | bx, |
| const amrex::Box & | gbx, | ||
| const int | ioff, | ||
| const int | joff, | ||
| const amrex::Array4< amrex::Real > & | vel, | ||
| const amrex::Array4< amrex::Real const > & | vel_old, | ||
| const amrex::Array4< amrex::Real > & | rvel, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | Akv, | ||
| const amrex::Array4< amrex::Real > & | FC, | ||
| const amrex::Array4< amrex::Real const > & | sstr, | ||
| const amrex::Array4< amrex::Real const > & | bstr, | ||
| const amrex::Array4< amrex::Real const > & | z_r, | ||
| const amrex::Array4< amrex::Real const > & | pm, | ||
| const amrex::Array4< amrex::Real const > & | pn, | ||
| const int | iic, | ||
| const int | ntfirst, | ||
| const int | nnew, | ||
| int | nstp, | ||
| int | nrhs, | ||
| int | N, | ||
| const amrex::Real | lambda, | ||
| const amrex::Real | dt_lev | ||
| ) |
Update velocities or tracers with diffusion/viscosity as the last part of the prestep.
Called from prestep. The tracer update is a bit different from the u,v updates so we test for it, but checking if ioff=0 and joff=0. In some cases, though, we can recover the tracer update from the generic one by setting those indices. Setting icc and ntfirst identically for the tracers should be equivalent to setting ioff=0 and joff=0
- Parameters
-
[in] vel_bx tile box [in] gbx grown tile box [in] ioff offset in x direction [in] joff offset in y direction [out] vel velocity or scalar to update [in] vel_old velocity or scalar at last time [in,out] rvel velocity or scalar RHS [in] Hz vertical cell height [in] Akv vertical viscosity coefficient FC temporary [in] sstr surface flux [in] bstr bottom flux [in] z_r z coordinates at rho points [in] pm 1/dx [in] pn 1/dy [in] iic which time step we're on [in] ntfirst what is the first time step? [in] nnew index of time step to update [in] nstp index of last time step [in] nrhs index of RHS component [in] N number of vertical levels [in] lambda weighting coefficient for the newest (implicit) time step derivatives [in] dt_lev time step at this level
Definition at line 38 of file REMORA_prestep_diffusion.cpp.
Referenced by prestep().

◆ prestep_t_advection()
| void REMORA::prestep_t_advection | ( | int | lev, |
| const amrex::Box & | tbx, | ||
| const amrex::Box & | gbx, | ||
| const amrex::Array4< amrex::Real > & | tempold, | ||
| const amrex::Array4< amrex::Real > & | tempcache, | ||
| const amrex::Array4< amrex::Real > & | Hz, | ||
| const amrex::Array4< amrex::Real > & | Huon, | ||
| const amrex::Array4< amrex::Real > & | Hvom, | ||
| const amrex::Array4< amrex::Real > & | W, | ||
| const amrex::Array4< amrex::Real > & | DC, | ||
| const amrex::Array4< amrex::Real > & | FC, | ||
| const amrex::Array4< amrex::Real > & | sstore, | ||
| const amrex::Array4< amrex::Real const > & | z_w, | ||
| const amrex::Array4< amrex::Real const > & | h, | ||
| const amrex::Array4< amrex::Real const > & | pm, | ||
| const amrex::Array4< amrex::Real const > & | pn, | ||
| const amrex::Array4< amrex::Real const > & | msku, | ||
| const amrex::Array4< amrex::Real const > & | mskv, | ||
| const amrex::Array4< int const > & | river_pos, | ||
| const amrex::Array4< amrex::Real const > & | river_source, | ||
| int | iic, | ||
| int | ntfirst, | ||
| int | nrhs, | ||
| int | N, | ||
| const amrex::Real | dt_lev | ||
| ) |
Prestep advection calculations for the tracers.
- Parameters
-
[in] lev level to operate on [in] tbx tile box [in] gbx grown tile box [in] tempold scalar at last time [in] tempcache cached current time step's scalar value [in] Hz vertical cell height [in] Huon u-volume flux [in] Hvom v-volume flux [in] Akv vertical viscosity coefficient [in,out] W vertical velocity DC temporary FC temporary [out] tempstore scratch space for calculations on scalars [in] z_w z coordinates at w points [in] h bathymetry [in] pm 1/dx [in] pn 1/dy [in] msku land-sea mask on u-points [in] mskv land-sea mask on v-points [in] river_pos river positions [in] river_source river source data to add, if using [in] iic which time step we're on [in] ntfirst what is the first time step? [in] nrhs index of RHS component [in] N number of vertical levels [in] dt_lev time step at this level
Definition at line 35 of file REMORA_prestep_t_advection.cpp.
Referenced by prestep().

◆ print_banner()
|
static |
Definition at line 60 of file REMORA_console_io.cpp.
Referenced by main().

◆ print_error()
|
static |
Definition at line 43 of file REMORA_console_io.cpp.
Referenced by main().

◆ print_summary()
|
static |
◆ print_tpls()
|
static |
Definition at line 137 of file REMORA_console_io.cpp.
◆ print_usage()
|
static |
Definition at line 26 of file REMORA_console_io.cpp.
Referenced by main().

◆ prsgrd()
| void REMORA::prsgrd | ( | const amrex::Box & | bx, |
| const amrex::Box & | gbx, | ||
| const amrex::Box & | utbx, | ||
| const amrex::Box & | vtbx, | ||
| const amrex::Array4< amrex::Real > & | ru, | ||
| const amrex::Array4< amrex::Real > & | rv, | ||
| const amrex::Array4< amrex::Real const > & | pn, | ||
| const amrex::Array4< amrex::Real const > & | pm, | ||
| const amrex::Array4< amrex::Real const > & | rho, | ||
| const amrex::Array4< amrex::Real > & | FC, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | z_r, | ||
| const amrex::Array4< amrex::Real const > & | z_w, | ||
| const amrex::Array4< amrex::Real const > & | msku, | ||
| const amrex::Array4< amrex::Real const > & | mskv, | ||
| const int | nrhs, | ||
| const int | N | ||
| ) |
Calculate pressure gradient.
- Parameters
-
[in] phi_bx tilebox [in] phi_gbx grownbox [in] utbx u-nodal tilebox [in] vtbx v-nodal tilebox [out] ru u-velocity RHS [out] rv v-velocity RHS [in] pm 1/dx [in] pn 1/dy [in] rho density FC temporary [in] Hz vertical cell height [in] z_r z coordinates at rho points [in] z_w z coordinates at w points [in] msku land-sea mask on u-points [in] mskv land-sea mask on v-points [in] nrhs index of RHS component [in] N number of vertical levels
Definition at line 25 of file REMORA_prsgrd.cpp.
Referenced by setup_step().

◆ ReadCheckpointFile()
|
private |
read checkpoint file from disk
Definition at line 220 of file REMORA_Checkpoint.cpp.
Referenced by restart().

◆ ReadNCMultiFab()
|
private |
Read MultiFab in NetCDF format.
◆ ReadParameters()
|
private |
read in some parameters from inputs file
Definition at line 1544 of file REMORA.cpp.
Referenced by REMORA(), and REMORA().

◆ refinement_criteria_setup()
|
private |
Set refinement criteria.
Function to define the refinement criteria based on user input
Definition at line 128 of file REMORA_Tagging.cpp.
Referenced by REMORA(), and REMORA().


◆ RemakeLevel()
|
overridevirtual |
Remake an existing level using provided BoxArray and DistributionMapping and fill with existing fine and coarse data. Overrides the pure virtual function in AmrCore.
Remake an existing level using provided BoxArray and DistributionMapping and fill with existing fine and coarse data. overrides the pure virtual function in AmrCore
- Parameters
-
[in] lev level to make [in] time current time [in] ba BoxArray for the level [in] dm DistributionMapping for the level
Definition at line 157 of file REMORA_make_new_level.cpp.
◆ remora_advance()
| void REMORA::remora_advance | ( | int | level, |
| amrex::MultiFab & | cons_old, | ||
| amrex::MultiFab & | cons_new, | ||
| amrex::MultiFab & | xvel_old, | ||
| amrex::MultiFab & | yvel_old, | ||
| amrex::MultiFab & | zvel_old, | ||
| amrex::MultiFab & | xvel_new, | ||
| amrex::MultiFab & | yvel_new, | ||
| amrex::MultiFab & | zvel_new, | ||
| amrex::MultiFab & | source, | ||
| const amrex::Geometry | fine_geom, | ||
| const amrex::Real | dt, | ||
| const amrex::Real | time | ||
| ) |
Interface for advancing the data at one level by one "slow" timestep.
◆ resize_stuff()
|
private |
Resize variable containers to accommodate data on levels 0 to max_lev.
- Parameters
-
[in] lev level do operate on
Definition at line 396 of file REMORA_make_new_level.cpp.
Referenced by MakeNewLevelFromCoarse(), and MakeNewLevelFromScratch().

◆ restart()
| void REMORA::restart | ( | ) |
\briefRestart
Definition at line 577 of file REMORA.cpp.
Referenced by InitData().
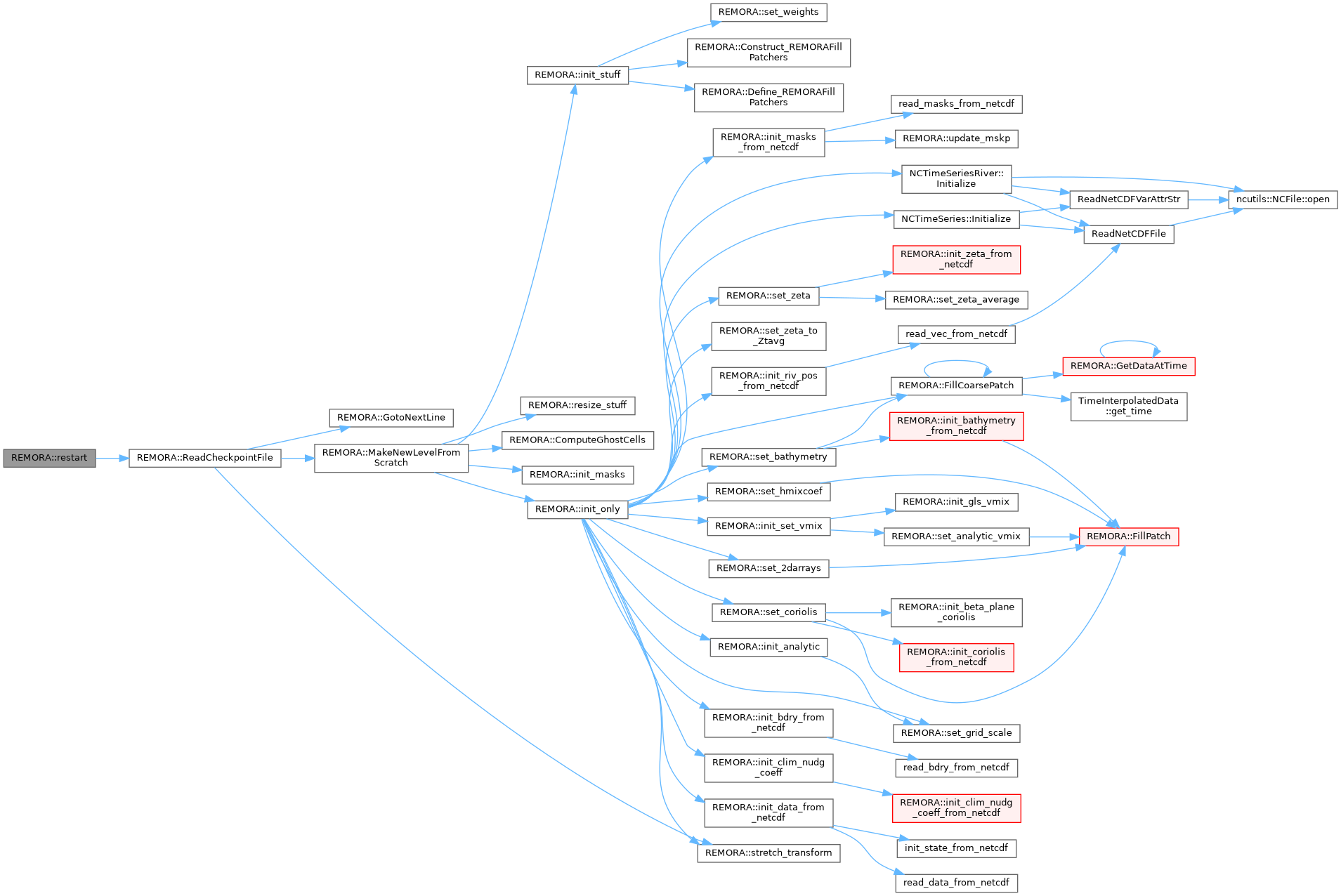

◆ rho_eos()
| void REMORA::rho_eos | ( | const amrex::Box & | bx, |
| const amrex::Array4< amrex::Real const > & | state, | ||
| const amrex::Array4< amrex::Real > & | rho, | ||
| const amrex::Array4< amrex::Real > & | rhoA, | ||
| const amrex::Array4< amrex::Real > & | rhoS, | ||
| const amrex::Array4< amrex::Real > & | bvf, | ||
| const amrex::Array4< amrex::Real > & | alpha, | ||
| const amrex::Array4< amrex::Real > & | beta, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | z_w, | ||
| const amrex::Array4< amrex::Real const > & | z_r, | ||
| const amrex::Array4< amrex::Real const > & | h, | ||
| const amrex::Array4< amrex::Real const > & | mskr, | ||
| const int | N | ||
| ) |
Wrapper around equation of state calculation.
- Parameters
-
[in] bx box for calculation [in] state state holds temp, salt [out] rho density [out] rhoA vertically-averaged density [out] rhoS density perturbation [out] bvf Brunt-Vaisala frequency [out] alpha thermal expansion coefficient [out] beta saline contraction coefficient [in] Hz vertical cell height [in] z_r z coordinates at rho points [in] z_w z coordinates at w points [in] h bathymetry [in] mskr land-sea mask on rho points [in] N number of vertical levels
Definition at line 22 of file REMORA_rho_eos.cpp.
Referenced by setup_step().


◆ rhs_t_3d()
| void REMORA::rhs_t_3d | ( | int | lev, |
| const amrex::Box & | bx, | ||
| const amrex::Array4< amrex::Real > & | t, | ||
| const amrex::Array4< amrex::Real const > & | tempstore, | ||
| const amrex::Array4< amrex::Real const > & | Huon, | ||
| const amrex::Array4< amrex::Real const > & | Hvom, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | pn, | ||
| const amrex::Array4< amrex::Real const > & | pm, | ||
| const amrex::Array4< amrex::Real const > & | W, | ||
| const amrex::Array4< amrex::Real > & | FC, | ||
| const amrex::Array4< amrex::Real const > & | mskr, | ||
| const amrex::Array4< amrex::Real const > & | msku, | ||
| const amrex::Array4< amrex::Real const > & | mskv, | ||
| const amrex::Array4< int const > & | river_pos, | ||
| const amrex::Array4< amrex::Real const > & | river_source, | ||
| int | nrhs, | ||
| int | nnew, | ||
| int | N, | ||
| const amrex::Real | dt_lev | ||
| ) |
RHS terms for tracer.
- Parameters
-
[in] lev level to operate on [in] bx tilebox [in,out] t tracer data [in] sstore scratch space for tracer calculations [in] Huon u-volume flux [in] Hvom v-volume flux [in] Hz vertical cell height [in] pn 1/dx [in] pm 1/dy [in] W vertical velocity FC temporary [in] mskr land-sea mask on rho-points [in] msku land-sea mask on u-points [in] mskv land-sea mask on v-points [in] river_pos river positions [in] river_source river source data to add, if using [in] nrhs index of RHS component [in] nnew index of current time step [in] N number of vertical levels [in] dt_lev time step at this level
Definition at line 28 of file REMORA_rhs_t_3d.cpp.
Referenced by advance_3d().

◆ rhs_uv_2d()
| void REMORA::rhs_uv_2d | ( | int | lev, |
| const amrex::Box & | xbx, | ||
| const amrex::Box & | ybx, | ||
| const amrex::Array4< amrex::Real const > & | uold, | ||
| const amrex::Array4< amrex::Real const > & | vold, | ||
| const amrex::Array4< amrex::Real > & | ru, | ||
| const amrex::Array4< amrex::Real > & | rv, | ||
| const amrex::Array4< amrex::Real const > & | Duon, | ||
| const amrex::Array4< amrex::Real const > & | Dvom, | ||
| const int | nrhs | ||
| ) |
RHS terms for 2D momentum.
- Parameters
-
[in] lev level to operate on [in] xbx Box for operations on x-velocity [in] ybx Box for operations on y-velocity [in] ubar barotropic x-velocity [in] vbar barotropic y-velocity [in,out] rhs_ubar RHS for barotropic x-velocity [in,out] rhs_vbar RHS for barotropic y-velocity [in] DUon u-volume flux (barotropic) [in] DVom v-volume flux (barotropic) [in] krhs index of rhs component
Definition at line 18 of file REMORA_rhs_uv_2d.cpp.
Referenced by advance_2d().


◆ rhs_uv_3d()
| void REMORA::rhs_uv_3d | ( | int | lev, |
| const amrex::Box & | xbx, | ||
| const amrex::Box & | ybx, | ||
| const amrex::Array4< amrex::Real const > & | uold, | ||
| const amrex::Array4< amrex::Real const > & | vold, | ||
| const amrex::Array4< amrex::Real > & | ru, | ||
| const amrex::Array4< amrex::Real > & | rv, | ||
| const amrex::Array4< amrex::Real > & | rufrc, | ||
| const amrex::Array4< amrex::Real > & | rvfrc, | ||
| const amrex::Array4< amrex::Real const > & | sustr, | ||
| const amrex::Array4< amrex::Real const > & | svstr, | ||
| const amrex::Array4< amrex::Real const > & | bustr, | ||
| const amrex::Array4< amrex::Real const > & | bvstr, | ||
| const amrex::Array4< amrex::Real const > & | Huon, | ||
| const amrex::Array4< amrex::Real const > & | Hvom, | ||
| const amrex::Array4< amrex::Real const > & | pm, | ||
| const amrex::Array4< amrex::Real const > & | pn, | ||
| const amrex::Array4< amrex::Real const > & | W, | ||
| const amrex::Array4< amrex::Real > & | FC, | ||
| int | nrhs, | ||
| int | N | ||
| ) |
RHS terms for 3D momentum.
- Parameters
-
[in] lev level to operate on [in] xbx Box for operations on x-velocity [in] ybx Box for operations on y-velocity [in] uold u-velocity at last time step [in] vold v-velocity at last time step [in,out] ru u-velocity RHS [in,out] rv v-velocity RHS [in,out] rufrc forcing for u-velocity RHS [in,out] rvfrc forcing for v-velocity RHS [in] sustr u-direction surface momentum flux [in] svstr v-direction surface momentum flux [in] bustr u-direction bottom stress [in] bvstr v-direction bottom stress [in] Huon u-volume flux [in] Hvom v-volume flux [in] pm 1/dx [in] pn 1/dy [in] W vertical velocity FC temporary [in] nrhs index of component for RHS [in] N number of vertical levels
Definition at line 29 of file REMORA_rhs_uv_3d.cpp.
Referenced by setup_step().

◆ scale_rhs_vars()
| void REMORA::scale_rhs_vars | ( | ) |
Scale RHS momentum variables by 1/cell area, needed before FillPatch to different levels.
Definition at line 6 of file REMORA_scale_rhs_vars.cpp.
Referenced by timeStep(), and timeStepML().

◆ scale_rhs_vars_inv()
| void REMORA::scale_rhs_vars_inv | ( | ) |
Scale RHS momentum variables by cell area, needed after FillPatch to different levels.
Definition at line 55 of file REMORA_scale_rhs_vars.cpp.
Referenced by timeStep(), and timeStepML().

◆ set2DPlotVariables()
|
private |
- Parameters
-
pp_plot_var_names_2d list of variable names to plot read in from parameter file
Definition at line 104 of file REMORA_SetPlotVars.cpp.
Referenced by REMORA(), and REMORA().


◆ set3DPlotVariables()
|
private |
- Parameters
-
pp_plot_var_names_3d list of variable names to plot read in from parameter file
Definition at line 16 of file REMORA_SetPlotVars.cpp.
Referenced by REMORA(), and REMORA().


◆ set_2darrays()
| void REMORA::set_2darrays | ( | int | lev | ) |
Set 2D momentum arrays from 3D momentum.
- Parameters
-
[in] lev level to operate on
Definition at line 82 of file REMORA_init.cpp.
Referenced by init_only().


◆ set_analytic_vmix()
| void REMORA::set_analytic_vmix | ( | int | lev | ) |
Set vertical mixing coefficients from analytic.
- Parameters
-
[in] lev level to operate on
Definition at line 791 of file REMORA.cpp.
Referenced by init_set_vmix(), and setup_step().


◆ set_bathymetry()
| void REMORA::set_bathymetry | ( | int | lev | ) |
Initialize bathymetry from file or analytic.
- Parameters
-
[in] lev level to operate on
Definition at line 629 of file REMORA.cpp.
Referenced by init_only().


◆ set_bathymetry_averaged_down()
| void REMORA::set_bathymetry_averaged_down | ( | int | lev | ) |
Copy over bathymetry data that has been averaged down from high resolution input netcdf file.
- Parameters
-
[in] lev level to operate on
Definition at line 682 of file REMORA.cpp.
Referenced by MakeNewLevelFromCoarse(), RemakeLevel(), and set_bathymetry().


◆ set_coriolis()
| void REMORA::set_coriolis | ( | int | lev | ) |
Initialize Coriolis factor from file or analytic.
- Parameters
-
[in] lev level to operate on
Definition at line 745 of file REMORA.cpp.
Referenced by init_only(), MakeNewLevelFromCoarse(), and RemakeLevel().


◆ set_curvilinear_terms_from_grid_scale()
| void REMORA::set_curvilinear_terms_from_grid_scale | ( | int | lev | ) |
Set curvilinear derivative terms on level lev based on pm and pn.
- Parameters
-
[in]
level to operate on
Definition at line 869 of file REMORA_make_new_level.cpp.
Referenced by set_grid_scale().

◆ set_drag()
| void REMORA::set_drag | ( | int | lev | ) |
Initialize or calculate bottom drag.
◆ set_grid_coords_from_grid_scale()
| void REMORA::set_grid_coords_from_grid_scale | ( | int | lev | ) |
Set x/y coords on level lev based on pm and pn.
- Parameters
-
[in]
level to operate on
Definition at line 824 of file REMORA_make_new_level.cpp.
Referenced by set_grid_scale().

◆ set_grid_scale()
| void REMORA::set_grid_scale | ( | int | lev | ) |
Set pm and pn arrays and x/y coords on level lev.
- Parameters
-
[in] lev level to operate on
Definition at line 769 of file REMORA_make_new_level.cpp.
Referenced by init_analytic(), init_only(), MakeNewLevelFromCoarse(), RemakeLevel(), and set_bathymetry().


◆ set_grid_vars_averaged_down()
| void REMORA::set_grid_vars_averaged_down | ( | int | lev | ) |
Set pm/pn by averaging down from higher-resolution grid.
- Parameters
-
[in] lev level to operate on
Definition at line 699 of file REMORA.cpp.
Referenced by set_bathymetry(), and set_grid_scale().


◆ set_hmixcoef()
| void REMORA::set_hmixcoef | ( | int | lev | ) |
Initialize horizontal mixing coefficients.
- Parameters
-
[in] lev level to operate on
Definition at line 833 of file REMORA.cpp.
Referenced by init_only(), MakeNewLevelFromCoarse(), and RemakeLevel().


◆ set_init_data_averaged_down()
| void REMORA::set_init_data_averaged_down | ( | int | lev | ) |
Problem initialization from averaged-down high resolution data.
- Parameters
-
[in] lev level to operate on
Definition at line 728 of file REMORA.cpp.
Referenced by init_only().


◆ set_masks()
| void REMORA::set_masks | ( | int | lev | ) |
Initialize land-sea masks from file or analytic.
- Parameters
-
[in] lev level to operate on
Definition at line 807 of file REMORA.cpp.
Referenced by init_only().


◆ set_smflux()
| void REMORA::set_smflux | ( | int | lev | ) |
Initialize or calculate surface momentum flux from file or analytic.
- Parameters
-
[in] lev level to operate on
Definition at line 1128 of file REMORA.cpp.
Referenced by setup_step().


◆ set_weights()
| void REMORA::set_weights | ( | int | lev | ) |
Set weights for averaging 3D variables to 2D.
- Parameters
-
[in] lev level to operate on
Definition at line 11 of file REMORA_set_weights.cpp.
Referenced by init_stuff().

◆ set_wind()
| void REMORA::set_wind | ( | int | lev | ) |
Initialize or calculate wind speed from file or analytic.
- Parameters
-
[in] lev level to operate on
Definition at line 1147 of file REMORA.cpp.
Referenced by setup_step().


◆ set_zeta()
| void REMORA::set_zeta | ( | int | lev | ) |
Initialize zeta from file or analytic.
- Parameters
-
[in] lev level to operate on
Definition at line 590 of file REMORA.cpp.
Referenced by init_only().


◆ set_zeta_average()
| void REMORA::set_zeta_average | ( | int | lev | ) |
Set Zt_avg1 to zeta.
- Parameters
-
[in] lev level to operate on
Definition at line 58 of file REMORA_init.cpp.
Referenced by set_zeta().

◆ set_zeta_averaged_down()
| void REMORA::set_zeta_averaged_down | ( | int | lev | ) |
Copy over zeta data that has been averaged down from high res.
- Parameters
-
[in] lev level to operate on
Definition at line 717 of file REMORA.cpp.
Referenced by set_zeta().


◆ set_zeta_to_Ztavg()
| void REMORA::set_zeta_to_Ztavg | ( | int | lev | ) |
Set zeta components to be equal to time-averaged Zt_avg1.
- Parameters
-
[in] lev level to operate on
Definition at line 890 of file REMORA_make_new_level.cpp.
Referenced by init_only(), MakeNewLevelFromCoarse(), RemakeLevel(), and setup_step().

◆ setRecordDataInfo()
|
inlineprivate |
Definition at line 1709 of file REMORA.H.
Referenced by ReadParameters().

◆ setup_step()
| void REMORA::setup_step | ( | int | lev, |
| amrex::Real | time, | ||
| amrex::Real | dt_lev | ||
| ) |
Set everything up for a step on a level.
- Parameters
-
[in] lev level to operate on [in] time time at start of step [in] dt_lev time step at level
Definition at line 11 of file REMORA_setup_step.cpp.
Referenced by Advance(), and timeStepML().
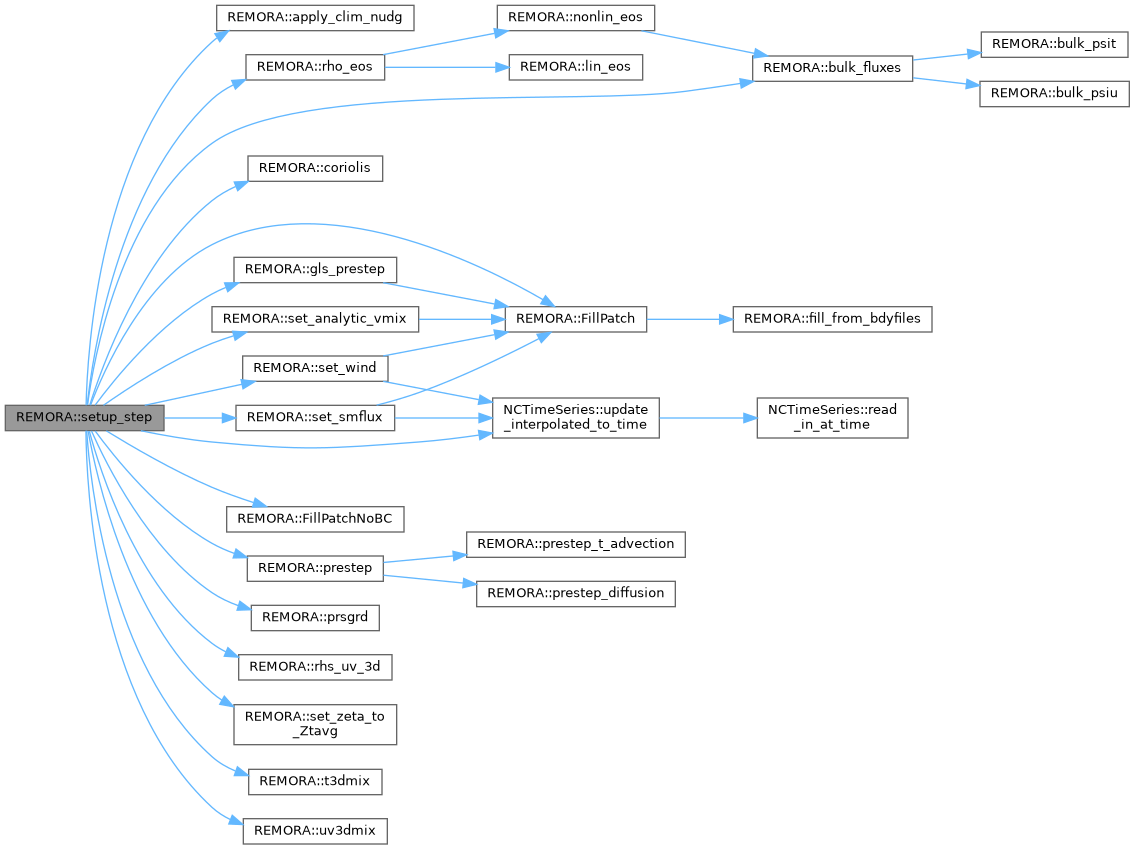

◆ stretch_transform()
| void REMORA::stretch_transform | ( | int | lev | ) |
Calculate vertical stretched coordinates.
- Parameters
-
[in] lev level to operate on
Definition at line 78 of file REMORA_DepthStretchTransform.H.
Referenced by advance_3d(), AverageDownTo(), init_only(), MakeNewLevelFromCoarse(), ReadCheckpointFile(), and RemakeLevel().
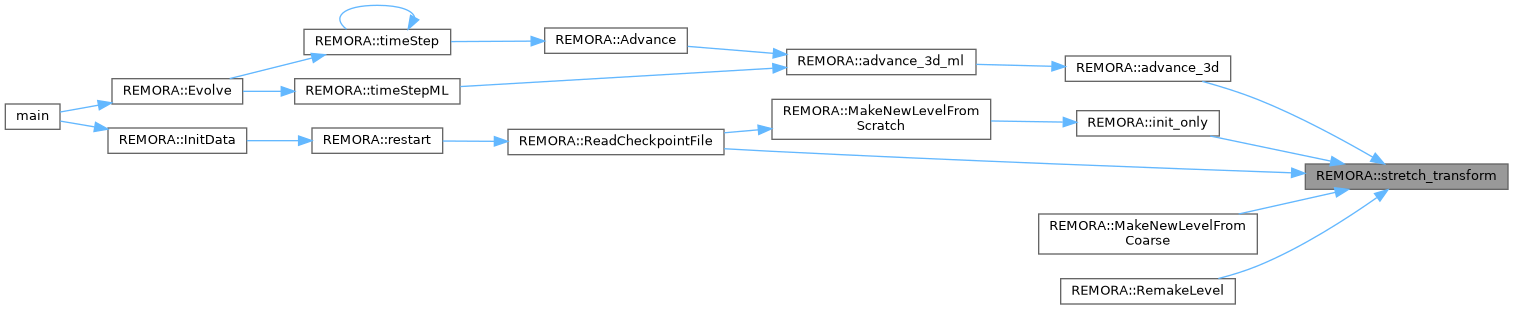
◆ sum_integrated_quantities()
| void REMORA::sum_integrated_quantities | ( | amrex::Real | time | ) |
Integrate conserved quantities for diagnostics.
- Parameters
-
[in] time current time
Definition at line 11 of file REMORA_SumIQ.cpp.
Referenced by InitData(), and post_timestep().
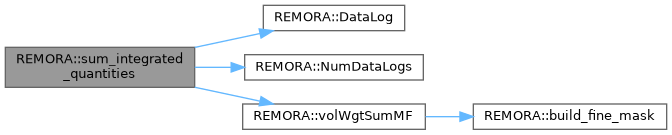

◆ t3dmix2()
| void REMORA::t3dmix2 | ( | const amrex::Box & | bx, |
| const amrex::Array4< amrex::Real > & | state, | ||
| const amrex::Array4< amrex::Real > & | state_rhs, | ||
| const amrex::Array4< amrex::Real const > & | diff2, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | z_r, | ||
| const amrex::Array4< amrex::Real const > & | pm, | ||
| const amrex::Array4< amrex::Real const > & | pn, | ||
| const amrex::Array4< amrex::Real const > & | msku, | ||
| const amrex::Array4< amrex::Real const > & | mskv, | ||
| const amrex::Real | dt_lev, | ||
| const int | ncomp, | ||
| const int | N | ||
| ) |
Wrapper for harmonic diffusivity for tracers.
- Parameters
-
[in] bx box to operate on [in,out] state scalar data [out] state_rhs scalar data RHS [in] diff2 diffusivity [in] Hz vertical cell height [in] z_r rho-point z coordinate [in] pm 1/dx [in] pn 1/dy [in] msku land-sea mask on u-points [in] mskv land-sea mask on v-points [in] dt_lev time step at level [in] ncomp number of components to do this calculation on [in] N number of vertical levels
Definition at line 21 of file REMORA_t3dmix.cpp.
Referenced by setup_step().

◆ t3dmix2_geo()
| void REMORA::t3dmix2_geo | ( | const amrex::Box & | bx, |
| const amrex::Array4< amrex::Real > & | state, | ||
| const amrex::Array4< amrex::Real > & | state_rhs, | ||
| const amrex::Array4< amrex::Real const > & | diff2, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | z_r, | ||
| const amrex::Array4< amrex::Real const > & | pm, | ||
| const amrex::Array4< amrex::Real const > & | pn, | ||
| const amrex::Array4< amrex::Real const > & | msku, | ||
| const amrex::Array4< amrex::Real const > & | mskv, | ||
| const amrex::Real | dt_lev, | ||
| const int | ncomp, | ||
| const int | N | ||
| ) |
Harmonic diffusivity for tracers along geopotential surfaces.
- Parameters
-
[in] bx box to operate on [in,out] state scalar data [out] state_rhs scalar data RHS [in] diff2 diffusivity [in] Hz vertical cell height [in] z_r rho-point z coordinates [in] pm 1/dx [in] pn 1/dy [in] msku land-sea mask on u-points [in] mskv land-sea mask on v-points [in] dt_lev time step at level [in] ncomp number of components to do this calculation on [in] N number of vertical levels
Definition at line 126 of file REMORA_t3dmix.cpp.
Referenced by t3dmix2().

◆ t3dmix2_s()
| void REMORA::t3dmix2_s | ( | const amrex::Box & | bx, |
| const amrex::Array4< amrex::Real > & | state, | ||
| const amrex::Array4< amrex::Real > & | state_rhs, | ||
| const amrex::Array4< amrex::Real const > & | diff2, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | pm, | ||
| const amrex::Array4< amrex::Real const > & | pn, | ||
| const amrex::Array4< amrex::Real const > & | msku, | ||
| const amrex::Array4< amrex::Real const > & | mskv, | ||
| const amrex::Real | dt_lev, | ||
| const int | ncomp | ||
| ) |
Harmonic diffusivity for tracers along S-coordinate level surfaces.
- Parameters
-
[in] bx box to operate on [in,out] state scalar data [out] state_rhs scalar data RHS [in] diff2 diffusivity [in] Hz vertical cell height [in] pm 1/dx [in] pn 1/dy [in] msku land-sea mask on u-points [in] mskv land-sea mask on v-points [in] dt_lev time step at level [in] ncomp number of components to do this calculation on
Definition at line 55 of file REMORA_t3dmix.cpp.
Referenced by t3dmix2().

◆ timeStep()
|
private |
advance a level by dt, includes a recursive call for finer levels
- Parameters
-
[in] lev level of refinement [in] time simulation time at start of step [in] iteration iteration in subcycling, if using
Definition at line 11 of file REMORA_TimeStep.cpp.
Referenced by Evolve(), EvolveOneStep(), and timeStep().

◆ timeStepML()
|
private |
advance all levels by dt, loops over finer levels
- Parameters
-
[in] time simulation time at start of step [in] iteration iteration in subcycling, if using
Definition at line 10 of file REMORA_TimeStepML.cpp.
Referenced by Evolve(), and EvolveOneStep().

◆ tke_bc()
|
inlinenoexcept |
Definition at line 1175 of file REMORA.H.
Referenced by init_bcs().


◆ u2d_simple_bc()
|
inlinenoexcept |
Definition at line 1178 of file REMORA.H.
Referenced by init_bcs(), and setup_step().


◆ ubar_bc()
|
inlinenoexcept |
Definition at line 1172 of file REMORA.H.
Referenced by advance_2d(), fill_from_bdyfiles(), init_bcs(), MakeNewLevelFromCoarse(), RemakeLevel(), and set_2darrays().

◆ update_massflux_3d()
| void REMORA::update_massflux_3d | ( | int | lev, |
| const amrex::Box & | bx, | ||
| const int | ioff, | ||
| const int | joff, | ||
| const amrex::Array4< amrex::Real > & | phi, | ||
| const amrex::Array4< amrex::Real > & | phibar, | ||
| const amrex::Array4< amrex::Real > & | Hphi, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | pm_or_pn, | ||
| const amrex::Array4< amrex::Real const > & | Dphi1, | ||
| const amrex::Array4< amrex::Real const > & | Dphi2, | ||
| const amrex::Array4< amrex::Real > & | DC, | ||
| const amrex::Array4< amrex::Real > & | FC, | ||
| const amrex::Array4< amrex::Real const > & | msk, | ||
| const int | nnew | ||
| ) |
Correct mass flux.
- Parameters
-
[in] lev level of refinement (coarsest level is 0) [in] bx box on which to update [in] ioff offset in x-direction [in] joff offset in y-direction [in,out] phi u or v [in,out] phibar ubar or vbar [in,out] Hphi phi-volume flux [in] Hz vertical cell height [in] pm_or_pn pm or pn [in] Dphi_avg1 DU_avg1 or DV_avg1 [in] Dphi_avg2 DU_avg2 or DV_avg2 DC temporary FC temporary [in] msk land-sea mask [in] nnew component of velocity
Definition at line 23 of file REMORA_update_massflux_3d.cpp.
Referenced by advance_3d().


◆ update_mskp()
| void REMORA::update_mskp | ( | int | lev | ) |
Set psi-point mask to be consistent with rho-point mask.
- Parameters
-
[in] lev level to operate on
Definition at line 941 of file REMORA_make_new_level.cpp.
Referenced by init_masks_from_netcdf().

◆ uv3dmix()
| void REMORA::uv3dmix | ( | const amrex::Box & | xbx, |
| const amrex::Box & | ybx, | ||
| const amrex::Array4< amrex::Real > & | u, | ||
| const amrex::Array4< amrex::Real > & | v, | ||
| const amrex::Array4< amrex::Real const > & | uold, | ||
| const amrex::Array4< amrex::Real const > & | vold, | ||
| const amrex::Array4< amrex::Real > & | rufrc, | ||
| const amrex::Array4< amrex::Real > & | rvfrc, | ||
| const amrex::Array4< amrex::Real const > & | visc2_p, | ||
| const amrex::Array4< amrex::Real const > & | visc2_r, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | pm, | ||
| const amrex::Array4< amrex::Real const > & | pn, | ||
| const amrex::Array4< amrex::Real const > & | mskp, | ||
| int | nrhs, | ||
| int | nnew, | ||
| const amrex::Real | dt_lev | ||
| ) |
Harmonic viscosity.
- Parameters
-
[in] xbx x-nodal tile box [in] ybx y-nodal tile box [in,out] u u-direction velocity [in,out] v v-direction velocity [in] uold u-direction velocity at last step [in] vold v-direction velocity at last step [in,out] rufrc forcing term for u-velocity RHS [in,out] rvfrc forcing term for v-velocity RHS [in] visc2_p harmonic viscosity on psi points [in] visc2_r harmonic viscosity on rho points [in] Hz vertical cell height [in] pm 1/dx [in] pn 1/dy [in] mskp land-sea mask on psi-points [in] nrhs index of RHS component [in] nnew index of time step to update [in] dt_lev time step at this level
Definition at line 25 of file REMORA_uv3dmix.cpp.
Referenced by advance_2d(), and setup_step().

◆ v2d_simple_bc()
|
inlinenoexcept |
Definition at line 1179 of file REMORA.H.
Referenced by init_bcs(), and setup_step().


◆ vbar_bc()
|
inlinenoexcept |
Definition at line 1173 of file REMORA.H.
Referenced by advance_2d(), fill_from_bdyfiles(), init_bcs(), MakeNewLevelFromCoarse(), RemakeLevel(), and set_2darrays().

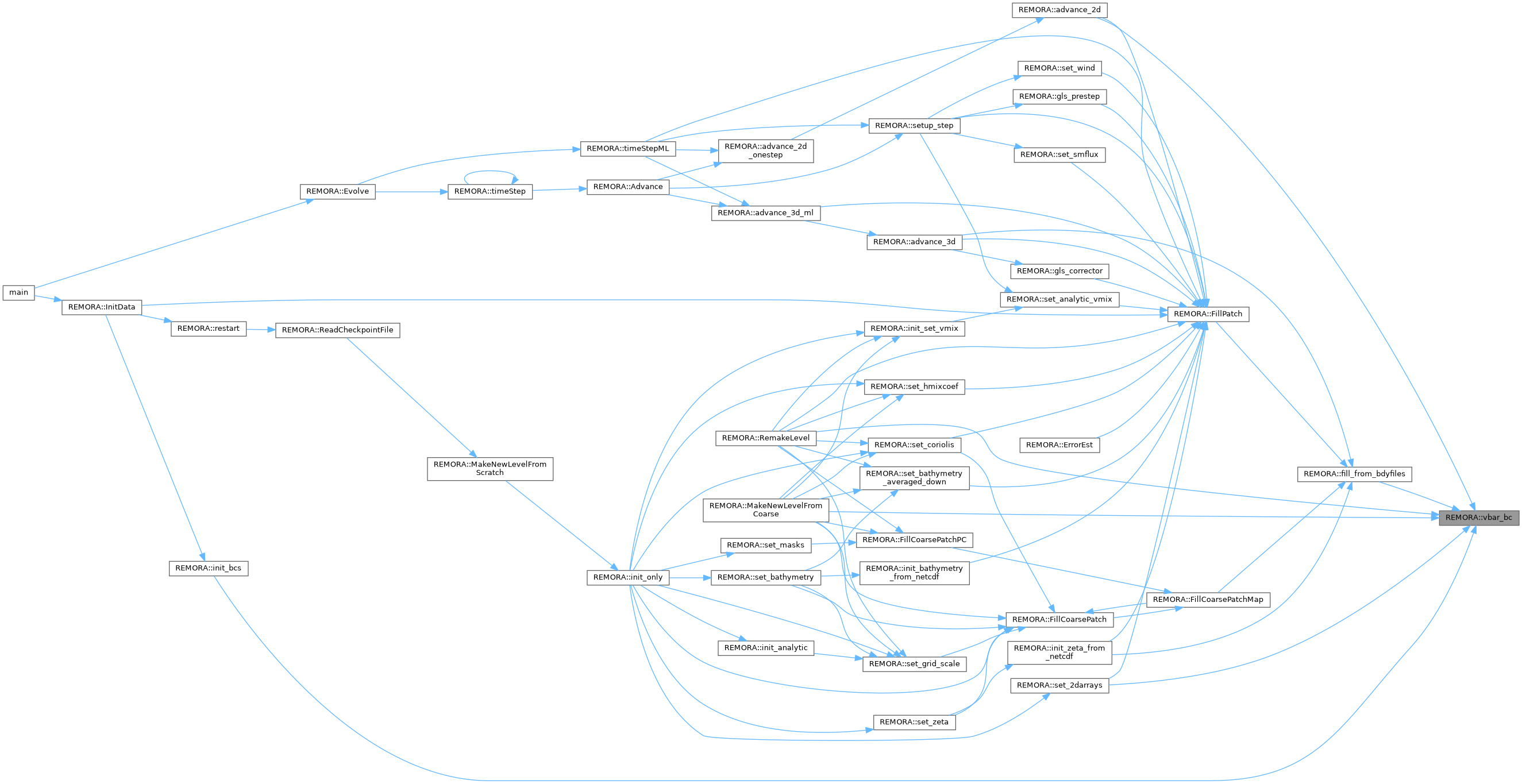
◆ vert_mean_3d()
| void REMORA::vert_mean_3d | ( | const amrex::Box & | bx, |
| const int | ioff, | ||
| const int | joff, | ||
| const amrex::Array4< amrex::Real > & | phi, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real const > & | Dphi_avg1, | ||
| const amrex::Array4< amrex::Real > & | DC, | ||
| const amrex::Array4< amrex::Real > & | CF, | ||
| const amrex::Array4< amrex::Real const > & | pm_or_pn, | ||
| const amrex::Array4< amrex::Real const > & | msk, | ||
| const int | nnew, | ||
| const int | N | ||
| ) |
Adjust 3D momentum variables based on vertical mean momentum.
- Parameters
-
[in] phi_bx box to update on [in] ioff x-direction offset [in] joff y-direction offset [in,out] phi velocity (u or v) [in] Dphi_avg1 time average of barotropic velocity DC temporary CF temporary [in] pm_or_pn 1/dx or 1/dy [in] msk land-sea mask [in] nnew index of time step to update [in] N number of vertical levels
Definition at line 19 of file REMORA_vert_mean_3d.cpp.
Referenced by advance_3d().

◆ vert_visc_3d()
| void REMORA::vert_visc_3d | ( | const amrex::Box & | bx, |
| const int | ioff, | ||
| const int | joff, | ||
| const amrex::Array4< amrex::Real > & | phi, | ||
| const amrex::Array4< amrex::Real const > & | Hz, | ||
| const amrex::Array4< amrex::Real > & | Hzk, | ||
| const amrex::Array4< amrex::Real > & | AK, | ||
| const amrex::Array4< amrex::Real const > & | Akv, | ||
| const amrex::Array4< amrex::Real > & | BC, | ||
| const amrex::Array4< amrex::Real > & | DC, | ||
| const amrex::Array4< amrex::Real > & | FC, | ||
| const amrex::Array4< amrex::Real > & | CF, | ||
| const int | nnew, | ||
| const int | N, | ||
| const amrex::Real | dt_lev | ||
| ) |
Calculate effects of vertical viscosity or diffusivity.
- Parameters
-
[in] phi_bx box to update on [in] ioff x-direction offset [in] joff y-direction offset [in,out] phi velocity (u or v) [in] Hz vertical height of cells Hzk temporary AK temporary [in] Akv vertical viscosity coefficient BC temporary DC temporary FC temporary CF temporary [in] nnew index of time step to update [in] N number of vertical levels [in] dt_lev time step at this refinement level
Definition at line 23 of file REMORA_vert_visc_3d.cpp.
Referenced by advance_3d().

◆ volWgtSumMF()
| Real REMORA::volWgtSumMF | ( | int | lev, |
| const amrex::MultiFab & | mf, | ||
| int | comp, | ||
| bool | local, | ||
| bool | finemask | ||
| ) |
Perform the volume-weighted sum.
- Parameters
-
[in] lev level to calculate on [in] mf data to sum over [in] comp component on which to calculate sum [in] local whether to do the sum locally [in] finemask whether to mask fine level
Definition at line 121 of file REMORA_SumIQ.cpp.
Referenced by sum_integrated_quantities().


◆ WriteAtFinalTime()
| void REMORA::WriteAtFinalTime | ( | ) |
Write checkpoint and plotfiles at end of simulation.
Definition at line 304 of file REMORA.cpp.
Referenced by Evolve().
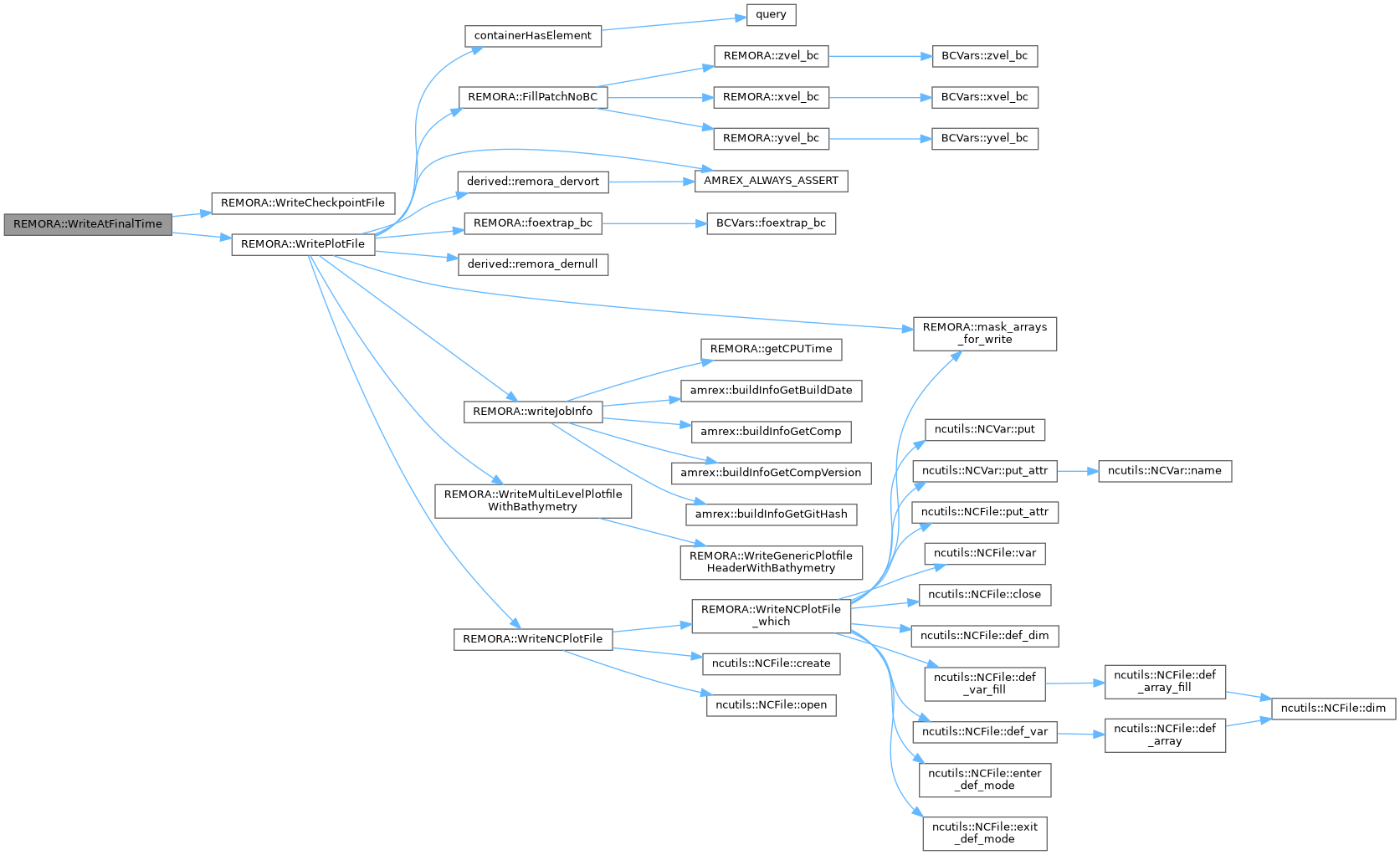

◆ WriteAtIntermediateTime()
| void REMORA::WriteAtIntermediateTime | ( | int | step, |
| amrex::Real | cur_time | ||
| ) |
Write checkpoint and plotfiles at intermediate point of simulation, if needed.
Definition at line 319 of file REMORA.cpp.
Referenced by Evolve(), and EvolveOneStep().
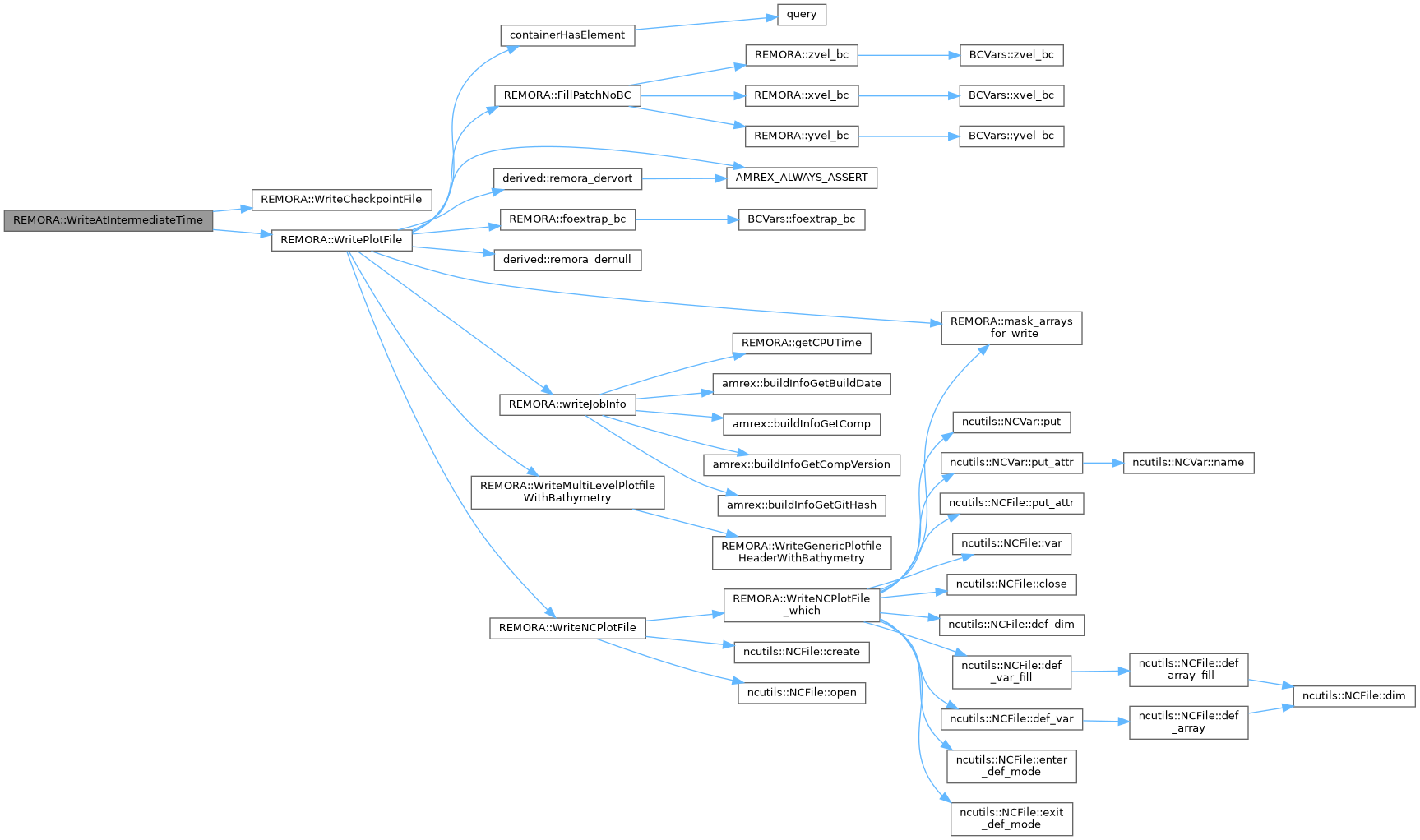

◆ writeBuildInfo()
|
static |
Write build info to os.
Definition at line 135 of file REMORA_writeJobInfo.cpp.
Referenced by main().
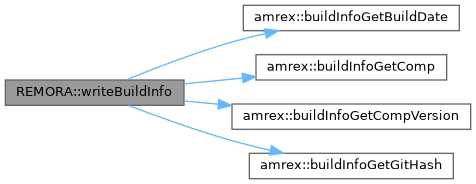

◆ WriteCheckpointFile()
|
private |
write checkpoint file to disk
Definition at line 15 of file REMORA_Checkpoint.cpp.
Referenced by InitData(), WriteAtFinalTime(), and WriteAtIntermediateTime().

◆ WriteGenericPlotfileHeaderWithBathymetry()
| void REMORA::WriteGenericPlotfileHeaderWithBathymetry | ( | std::ostream & | HeaderFile, |
| int | nlevels, | ||
| const amrex::Vector< amrex::BoxArray > & | bArray, | ||
| const amrex::Vector< std::string > & | varnames_3d, | ||
| const amrex::Vector< std::string > & | varnames_2d_rho, | ||
| const amrex::Vector< std::string > & | varnames_2d_u, | ||
| const amrex::Vector< std::string > & | varnames_2d_v, | ||
| const amrex::Vector< amrex::Geometry > & | my_geom, | ||
| amrex::Real | time, | ||
| const amrex::Vector< int > & | level_steps, | ||
| const amrex::Vector< amrex::IntVect > & | rr, | ||
| const std::string & | versionName, | ||
| const std::string & | levelPrefix, | ||
| const std::string & | mfPrefix | ||
| ) | const |
write out header data for an AMReX plotfile
- Parameters
-
HeaderFile output stream for header nlevels number of levels to write out bArray vector over levels of BoxArrays varnames_3d 3D variable names to write out varnames_2d 2D variable names to write out my_geom geometry to use for writing plotfile time time at which to output level_steps vector over level of iterations my_ref_ratio refinement ratio to use for writing plotfile versionName version string for VisIt levelPrefix string to prepend to level number mfPrefix subdirectory for multifab data
Definition at line 784 of file REMORA_Plotfile.cpp.
Referenced by WriteMultiLevelPlotfileWithBathymetry().

◆ writeJobInfo()
| void REMORA::writeJobInfo | ( | const std::string & | dir | ) | const |
Write job info to stdout.
Definition at line 7 of file REMORA_writeJobInfo.cpp.
Referenced by WritePlotFile().


◆ WriteMultiLevelPlotfileWithBathymetry()
| void REMORA::WriteMultiLevelPlotfileWithBathymetry | ( | const std::string & | plotfilename, |
| int | nlevels, | ||
| const amrex::Vector< const amrex::MultiFab * > & | mf, | ||
| const amrex::Vector< const amrex::MultiFab * > & | mf_nd, | ||
| const amrex::Vector< const amrex::MultiFab * > & | mf_u, | ||
| const amrex::Vector< const amrex::MultiFab * > & | mf_v, | ||
| const amrex::Vector< const amrex::MultiFab * > & | mf_w, | ||
| const amrex::Vector< const amrex::MultiFab * > & | mf_2d_rho, | ||
| const amrex::Vector< const amrex::MultiFab * > & | mf_2d_u, | ||
| const amrex::Vector< const amrex::MultiFab * > & | mf_2d_v, | ||
| const amrex::Vector< std::string > & | varnames_3d, | ||
| const amrex::Vector< std::string > & | varnames_2d_rho, | ||
| const amrex::Vector< std::string > & | varnames_2d_u, | ||
| const amrex::Vector< std::string > & | varnames_2d_v, | ||
| const amrex::Vector< amrex::Geometry > & | my_geom, | ||
| amrex::Real | time, | ||
| const amrex::Vector< int > & | level_steps, | ||
| const amrex::Vector< amrex::IntVect > & | rr, | ||
| const std::string & | versionName = "HyperCLaw-V1.1", |
||
| const std::string & | levelPrefix = "Level_", |
||
| const std::string & | mfPrefix = "Cell", |
||
| const amrex::Vector< std::string > & | extra_dirs = amrex::Vector<std::string>() |
||
| ) | const |
write out particular data to an AMReX plotfile
- Parameters
-
plotfilename name of plotfile to write to nlevels number of levels to write out mf MultiFab of data to write out mf_nd Multifab of nodal data to write out varnames_3d 3D variable names to write out varnames_2d_rho 2D cell-centered variable names to write out varnames_2d_u 2D x-face-based variable names to write out varnames_2d_v 2D y-face-based variable names to write out my_geom geometry to use for writing plotfile time time at which to output level_steps vector over level of iterations rr refinement ratio to use for writing plotfile versionName version string for VisIt levelPrefix string to prepend to level number mfPrefix subdirectory for multifab data extra_dirs additional subdirectories within plotfile
Definition at line 619 of file REMORA_Plotfile.cpp.
Referenced by WritePlotFile().


◆ WriteNCMultiFab()
|
private |
Write MultiFab in NetCDF format.
◆ WriteNCPlotFile()
|
private |
Write plotfile using NetCDF (wrapper)
- Parameters
-
which_step current step for output
Definition at line 24 of file REMORA_NCPlotFile.cpp.
Referenced by WritePlotFile().

◆ WriteNCPlotFile_which()
|
private |
Write a particular NetCDF plotfile.
- Parameters
-
lev level of data to output which_subdomain index of subdomain if lev != 0 write_header whether to write a header ncf netcdf file object is_history whether the file being written is a history file
Definition at line 109 of file REMORA_NCPlotFile.cpp.
Referenced by WriteNCPlotFile().

◆ WritePlotFile()
| void REMORA::WritePlotFile | ( | int | istep | ) |
main driver for writing AMReX plotfiles
Definition at line 16 of file REMORA_Plotfile.cpp.
Referenced by InitData(), timeStepML(), WriteAtFinalTime(), and WriteAtIntermediateTime().

◆ xvel_bc()
|
inlinenoexcept |
Definition at line 1169 of file REMORA.H.
Referenced by advance_3d(), ErrorEst(), FillBdyCCVels(), FillPatchNoBC(), gls_corrector(), gls_prestep(), init_bcs(), init_only(), InitData(), MakeNewLevelFromCoarse(), RemakeLevel(), rhs_uv_2d(), set_init_data_averaged_down(), timeStepML(), and update_massflux_3d().

◆ yvel_bc()
|
inlinenoexcept |
Definition at line 1170 of file REMORA.H.
Referenced by advance_3d(), ErrorEst(), FillBdyCCVels(), FillPatchNoBC(), gls_corrector(), gls_prestep(), init_bcs(), init_only(), InitData(), MakeNewLevelFromCoarse(), RemakeLevel(), rhs_uv_2d(), set_init_data_averaged_down(), timeStepML(), and update_massflux_3d().

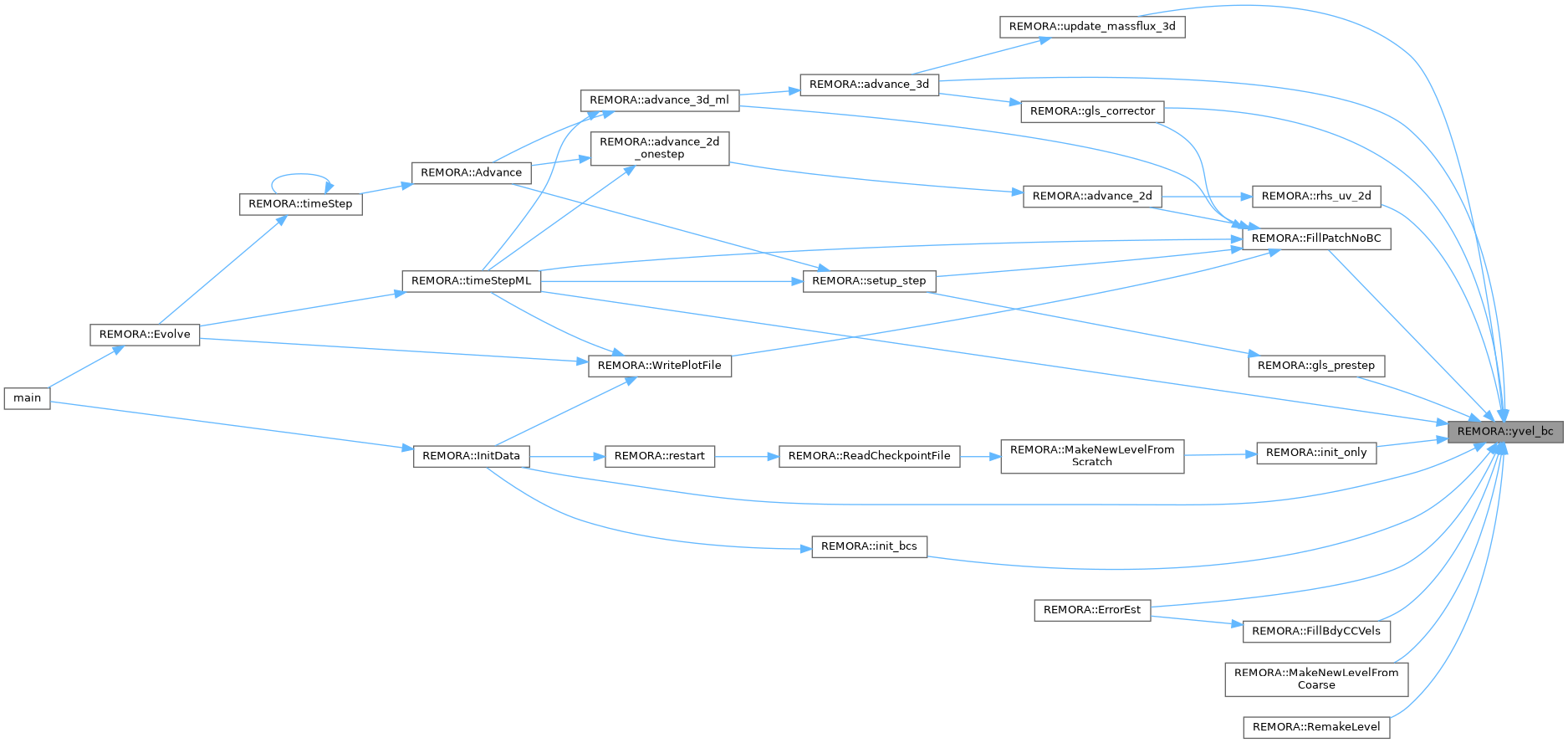
◆ zeta_bc()
|
inlinenoexcept |
Definition at line 1174 of file REMORA.H.
Referenced by advance_2d(), fill_from_bdyfiles(), init_bcs(), init_zeta_from_netcdf(), RemakeLevel(), and set_zeta_averaged_down().

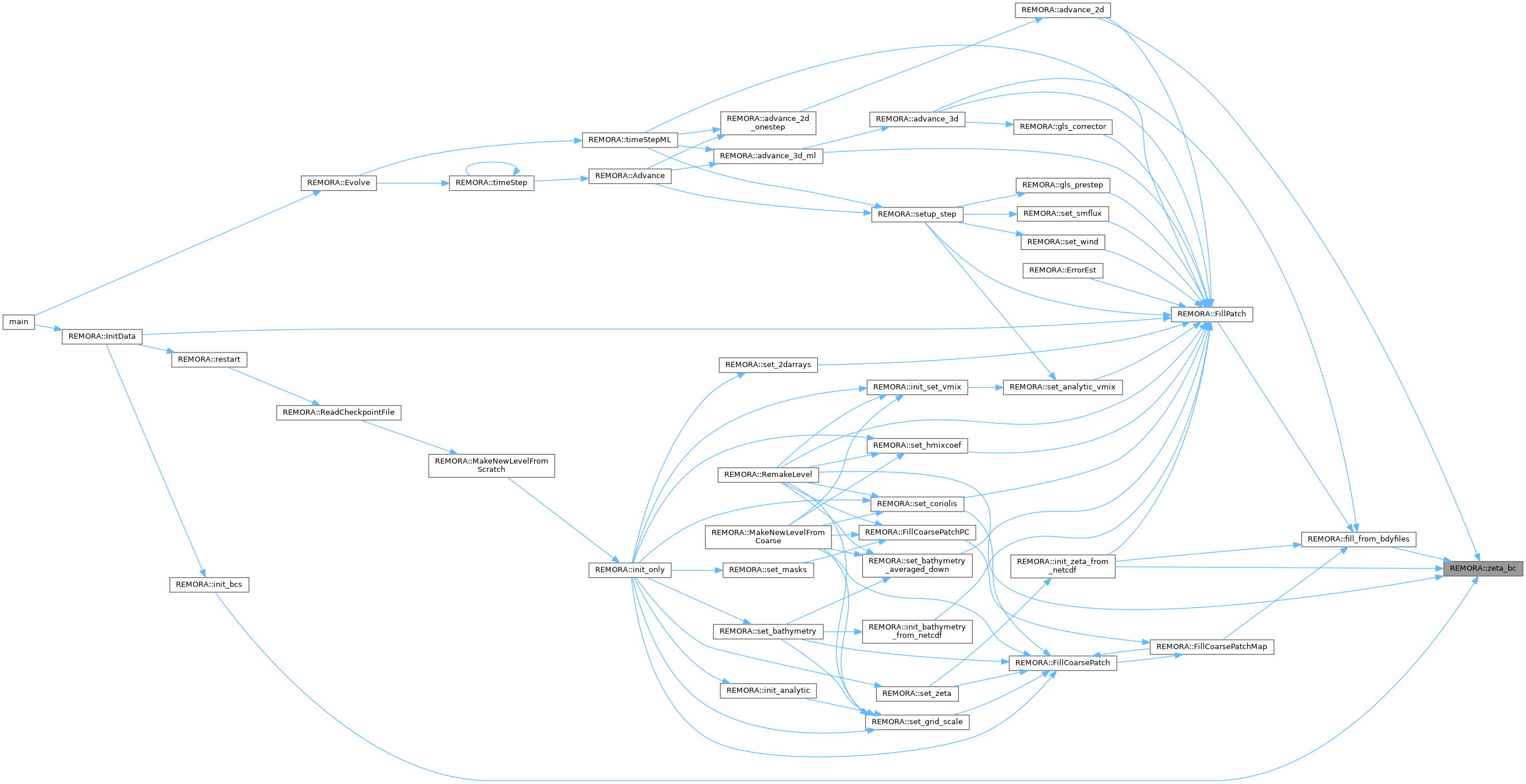
◆ zvel_bc()
|
inlinenoexcept |
Definition at line 1171 of file REMORA.H.
Referenced by advance_3d_ml(), ErrorEst(), FillBdyCCVels(), FillPatchNoBC(), gls_corrector(), gls_prestep(), init_bcs(), init_only(), InitData(), MakeNewLevelFromCoarse(), RemakeLevel(), set_analytic_vmix(), setup_step(), and timeStepML().

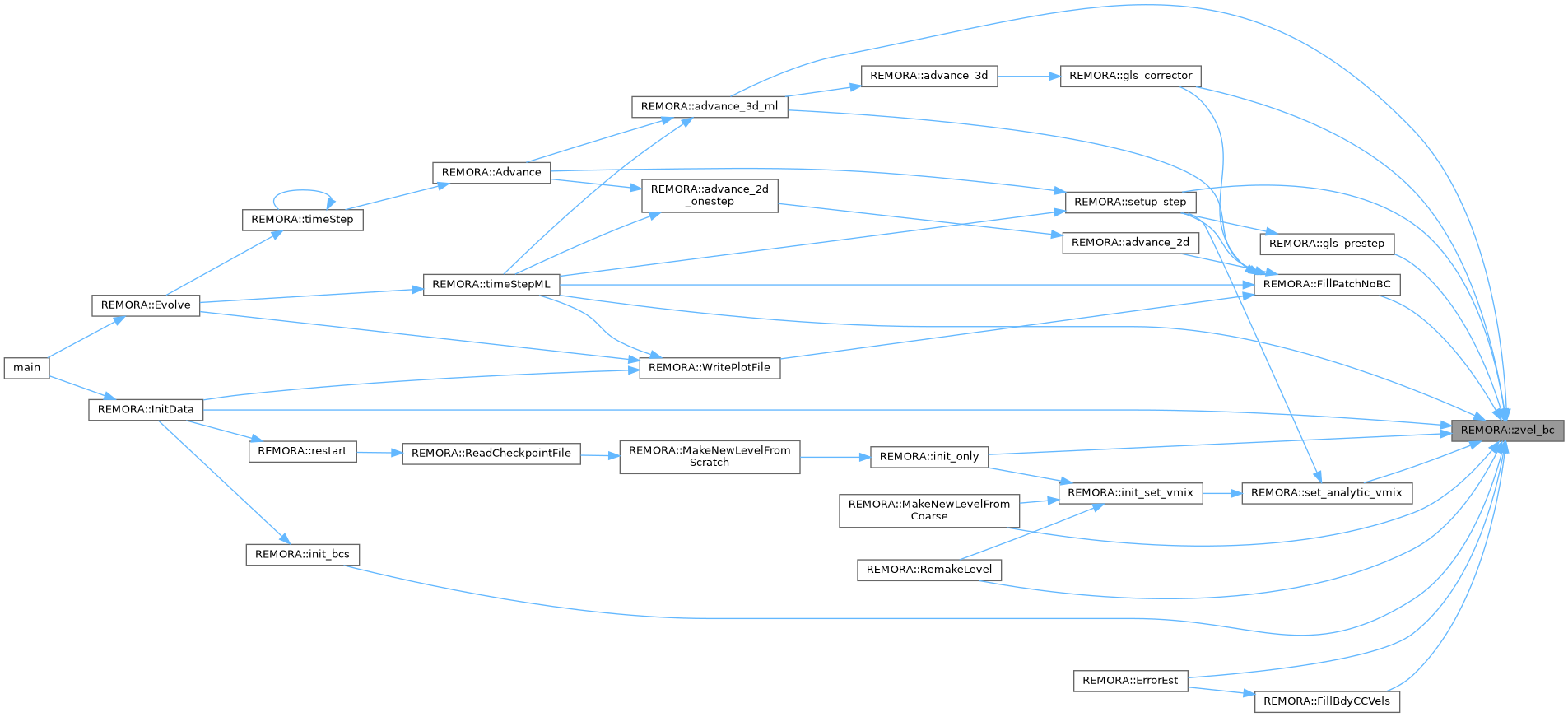
Member Data Documentation
◆ advflux_reg
|
private |
array of flux registers for refluxing in multilevel
Definition at line 1408 of file REMORA.H.
Referenced by InitData(), REMORA(), and REMORA().
◆ bdry_time_name_byvar
|
private |
Name of time fields for boundary data.
Definition at line 1617 of file REMORA.H.
Referenced by init_bdry_from_netcdf(), and ReadParameters().
◆ bdry_time_varname
|
private |
Default name of time field for boundary data.
Definition at line 1615 of file REMORA.H.
Referenced by ReadParameters().
◆ bdy_index
|
private |
Container to connect boundary data being read in boundary condition containers.
Needed for phys_bc_need_data to work correctly
Definition at line 1437 of file REMORA.H.
Referenced by init_bcs().
◆ bdy_time_interval
|
private |
Interval between boundary data times.
Definition at line 1278 of file REMORA.H.
Referenced by FillCoarsePatchMap().
◆ boundary_series
|
private |
Vector over BdyVars of boundary series data containers.
Definition at line 1329 of file REMORA.H.
Referenced by fill_from_bdyfiles(), init_bdry_from_netcdf(), and ReadParameters().
◆ boxes_at_level
|
private |
the boxes specified at each level by tagging criteria
Definition at line 1388 of file REMORA.H.
Referenced by init_bathymetry_from_netcdf(), init_clim_nudg_coeff_from_netcdf(), init_coriolis_from_netcdf(), init_data_from_netcdf(), init_grid_vars_from_netcdf(), init_masks_from_netcdf(), init_zeta_from_netcdf(), ReadParameters(), refinement_criteria_setup(), and WriteNCPlotFile_which().
◆ cf_set_width
|
private |
Width for fixing values at coarse-fine interface.
Definition at line 1345 of file REMORA.H.
Referenced by Construct_REMORAFillPatchers(), Define_REMORAFillPatchers(), FillPatch(), and FillPatchNoBC().
◆ cf_width
|
private |
Nudging width at coarse-fine interface.
Definition at line 1343 of file REMORA.H.
Referenced by Construct_REMORAFillPatchers(), Define_REMORAFillPatchers(), init_stuff(), InitData(), MakeNewLevelFromCoarse(), RemakeLevel(), and timeStepML().
◆ cfl
|
staticprivate |
CFL condition.
Definition at line 1472 of file REMORA.H.
Referenced by estTimeStep(), and ReadParameters().
◆ change_max
|
staticprivate |
Fraction maximum change in subsequent time steps.
Definition at line 1474 of file REMORA.H.
Referenced by ComputeDt(), and ReadParameters().
◆ check_file
|
private |
Checkpoint file prefix.
Definition at line 1498 of file REMORA.H.
Referenced by ReadParameters(), and WriteCheckpointFile().
◆ check_int
|
private |
Checkpoint output interval in iterations.
Definition at line 1500 of file REMORA.H.
Referenced by InitData(), ReadParameters(), WriteAtFinalTime(), and WriteAtIntermediateTime().
◆ check_int_time
|
private |
Checkpoint output interval in seconds.
Definition at line 1502 of file REMORA.H.
Referenced by InitData(), ReadParameters(), WriteAtFinalTime(), and WriteAtIntermediateTime().
◆ chunk_history_file
|
private |
Whether to chunk netcdf history file.
Definition at line 1505 of file REMORA.H.
Referenced by ReadParameters(), WriteNCPlotFile(), and WriteNCPlotFile_which().
◆ clim_salt_time_varname
|
private |
Name of time field for salinity climatology data.
Definition at line 1628 of file REMORA.H.
Referenced by init_only(), and ReadParameters().
◆ clim_temp_time_varname
|
private |
Name of time field for temperature climatology data.
Definition at line 1630 of file REMORA.H.
Referenced by init_only(), and ReadParameters().
◆ clim_u_time_varname
|
private |
Name of time field for u climatology data.
Definition at line 1624 of file REMORA.H.
Referenced by init_only(), and ReadParameters().
◆ clim_ubar_time_varname
|
private |
Name of time field for ubar climatology data.
Definition at line 1620 of file REMORA.H.
Referenced by init_only(), and ReadParameters().
◆ clim_v_time_varname
|
private |
Name of time field for v climatology data.
Definition at line 1626 of file REMORA.H.
Referenced by init_only(), and ReadParameters().
◆ clim_vbar_time_varname
|
private |
Name of time field for vbar climatology data.
Definition at line 1622 of file REMORA.H.
Referenced by ReadParameters().
◆ cloud_data_from_file
|
private |
Data container for cloud cover fraction read from file.
Definition at line 1304 of file REMORA.H.
Referenced by init_only(), and set_wind().
◆ cons_names
|
private |
Names of scalars for plotfile output.
Definition at line 1519 of file REMORA.H.
Referenced by init_scalar_metadata(), set2DPlotVariables(), set3DPlotVariables(), WriteNCPlotFile_which(), and WritePlotFile().
◆ cons_new
| amrex::Vector<amrex::MultiFab*> REMORA::cons_new |
multilevel data container for current step's scalar data: temperature, salinity, passive tracer
Definition at line 303 of file REMORA.H.
Referenced by advance_3d(), advance_3d_ml(), allocate_init_full_domain(), AverageDownTo(), ClearLevel(), Construct_REMORAFillPatchers(), Define_REMORAFillPatchers(), ErrorEst(), init_analytic(), init_bathymetry_from_netcdf(), init_beta_plane_coriolis(), init_clim_nudg_coeff_from_netcdf(), init_coriolis_from_netcdf(), init_data_from_netcdf(), init_grid_vars_from_netcdf(), init_masks_from_netcdf(), init_only(), init_zeta_from_netcdf(), InitData(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), mask_arrays_for_write(), PackSurfaceState(), ReadCheckpointFile(), RemakeLevel(), REMORA(), REMORA(), scale_rhs_vars(), scale_rhs_vars_inv(), set_2darrays(), set_grid_scale(), set_init_data_averaged_down(), set_zeta_average(), setup_step(), stretch_transform(), sum_integrated_quantities(), timeStep(), timeStepML(), volWgtSumMF(), WriteCheckpointFile(), and WritePlotFile().
◆ cons_old
| amrex::Vector<amrex::MultiFab*> REMORA::cons_old |
multilevel data container for last step's scalar data: temperature, salinity, passive tracer
Definition at line 294 of file REMORA.H.
Referenced by advance_3d(), ClearLevel(), gls_corrector(), InitData(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), ReadCheckpointFile(), RemakeLevel(), REMORA(), REMORA(), setup_step(), timeStep(), timeStepML(), and WriteCheckpointFile().
◆ Cs_r
| amrex::Gpu::DeviceVector<amrex::Real> REMORA::Cs_r |
Stretching coefficients at rho points.
Definition at line 373 of file REMORA.H.
Referenced by calc_stretch_coeffs(), init_stretch_coeffs(), stretch_transform(), and WriteNCPlotFile_which().
◆ Cs_w
| amrex::Gpu::DeviceVector<amrex::Real> REMORA::Cs_w |
Stretching coefficients at w points.
Definition at line 375 of file REMORA.H.
Referenced by calc_stretch_coeffs(), init_stretch_coeffs(), stretch_transform(), and WriteNCPlotFile_which().
◆ cum_ref_ratios
|
private |
Cumulative refinement ratio between level 0 and level i.
Definition at line 1602 of file REMORA.H.
Referenced by allocate_bathymetry_grid_vars_full_domain(), allocate_init_full_domain(), average_down_with_grow_cells(), init_bathymetry_full_domain_from_netcdf(), init_data_full_domain_from_netcdf(), init_grid_vars_full_domain_from_netcdf(), init_zeta_full_domain_from_netcdf(), and REMORA().
◆ datalog
|
private |
Definition at line 1722 of file REMORA.H.
Referenced by DataLog(), NumDataLogs(), ReadParameters(), and setRecordDataInfo().
◆ datalogname
|
private |
Definition at line 1723 of file REMORA.H.
Referenced by DataLogName(), and ReadParameters().
◆ derived_names
|
private |
Names of derived fields for plotfiles.
Definition at line 1522 of file REMORA.H.
Referenced by set2DPlotVariables(), and set3DPlotVariables().
◆ do_substep
|
private |
Whether to substep fine levels in time.
Definition at line 1485 of file REMORA.H.
Referenced by ReadParameters(), REMORA(), and REMORA().
◆ domain_bc_type
|
private |
Array of strings describing domain boundary conditions.
Definition at line 1422 of file REMORA.H.
Referenced by init_bcs(), and writeJobInfo().
◆ domain_bcs_type
|
private |
vector (over BCVars) of BCRecs
Definition at line 1417 of file REMORA.H.
Referenced by fill_from_bdyfiles(), FillCoarsePatchMap(), FillPatch(), FillPatchNoBC(), gls_corrector(), gls_prestep(), init_bcs(), init_stuff(), rhs_uv_2d(), update_massflux_3d(), and WritePlotFile().
◆ domain_bcs_type_d
|
private |
GPU vector (over BCVars) of BCRecs.
Definition at line 1419 of file REMORA.H.
Referenced by FillCoarsePatchMap(), init_bcs(), and init_stuff().
◆ driver_atmos_state_from_driver
| std::array<bool, AtmosState::NumTypes> REMORA::driver_atmos_state_from_driver {} |
provenance flags for driver-supplied atmospheric forcing lanes
Definition at line 429 of file REMORA.H.
Referenced by ApplyAtmosphericStates(), and set_wind().
◆ dt
|
private |
time step at each level
Definition at line 1399 of file REMORA.H.
Referenced by ComputeDt(), Evolve(), EvolveOneStep(), InitData(), ReadCheckpointFile(), REMORA(), REMORA(), set_zeta_to_Ztavg(), timeStep(), timeStepML(), and WriteCheckpointFile().
◆ EminusP_data_from_file
|
private |
Data container for evaporation minus precipitation read from file.
Definition at line 1306 of file REMORA.H.
Referenced by init_only(), and set_wind().
◆ expand_plotvars_to_unif_rr
|
private |
whether plotfile variables should be expanded to a uniform refinement ratio
Definition at line 1528 of file REMORA.H.
Referenced by ReadParameters(), and WritePlotFile().
◆ file_min_digits
|
staticprivate |
Minimum number of digits in plotfile name or chunked history file.
Definition at line 1569 of file REMORA.H.
Referenced by ReadParameters(), WriteCheckpointFile(), WriteNCPlotFile(), and WritePlotFile().
◆ fine_mask
|
private |
Mask that zeroes out values on a coarse level underlying grids on the next finest level.
Definition at line 1643 of file REMORA.H.
Referenced by build_fine_mask().
◆ fixed_dt
|
staticprivate |
User specified fixed baroclinic time step.
Definition at line 1476 of file REMORA.H.
Referenced by estTimeStep(), ReadParameters(), and set_weights().
◆ fixed_fast_dt
|
staticprivate |
User specified fixed barotropic time step.
Definition at line 1478 of file REMORA.H.
Referenced by ReadParameters(), and set_weights().
◆ fixed_ndtfast_ratio
|
staticprivate |
User specified, number of barotropic steps per baroclinic step.
Definition at line 1480 of file REMORA.H.
Referenced by Advance(), ReadParameters(), set_weights(), and timeStepML().
◆ FPr_c
|
private |
Vector over levels of FillPatchers for scalars.
Definition at line 1348 of file REMORA.H.
Referenced by Construct_REMORAFillPatchers(), Define_REMORAFillPatchers(), FillPatch(), FillPatchNoBC(), and timeStepML().
◆ FPr_u
|
private |
Vector over levels of FillPatchers for u (3D)
Definition at line 1350 of file REMORA.H.
Referenced by Construct_REMORAFillPatchers(), Define_REMORAFillPatchers(), FillPatch(), FillPatchNoBC(), and timeStepML().
◆ FPr_ubar
|
private |
Vector over levels of FillPatchers for ubar (2D)
Definition at line 1358 of file REMORA.H.
Referenced by Construct_REMORAFillPatchers(), Define_REMORAFillPatchers(), FillPatch(), FillPatchNoBC(), and timeStepML().
◆ FPr_v
|
private |
Vector over levels of FillPatchers for v (3D)
Definition at line 1352 of file REMORA.H.
Referenced by Construct_REMORAFillPatchers(), Define_REMORAFillPatchers(), FillPatch(), FillPatchNoBC(), and timeStepML().
◆ FPr_vbar
|
private |
Vector over levels of FillPatchers for vbar (2D)
Definition at line 1360 of file REMORA.H.
Referenced by Construct_REMORAFillPatchers(), Define_REMORAFillPatchers(), FillPatch(), FillPatchNoBC(), and timeStepML().
◆ FPr_w
|
private |
Vector over levels of FillPatchers for w.
Definition at line 1354 of file REMORA.H.
Referenced by Construct_REMORAFillPatchers(), Define_REMORAFillPatchers(), FillPatch(), FillPatchNoBC(), and timeStepML().
◆ frc_time_varname
|
private |
Name of time field for forcing data.
Definition at line 1634 of file REMORA.H.
Referenced by init_only(), and ReadParameters().
◆ hires_grid_level
|
private |
Which level the high resolution bathymetry is at.
Definition at line 1588 of file REMORA.H.
Referenced by allocate_bathymetry_grid_vars_full_domain(), init_bathymetry_full_domain_from_analytic(), init_bathymetry_full_domain_from_netcdf(), init_grid_vars_full_domain_from_netcdf(), init_only(), MakeNewLevelFromCoarse(), ReadParameters(), RemakeLevel(), resize_stuff(), set_bathymetry(), and set_grid_scale().
◆ hires_init_level
|
private |
Which level the high resolution initialization data is at.
Definition at line 1595 of file REMORA.H.
Referenced by allocate_init_full_domain(), init_data_full_domain_from_netcdf(), init_full_domain_from_analytic(), init_full_domain_zeta_from_analytic(), init_only(), init_zeta_full_domain_from_netcdf(), ReadParameters(), resize_stuff(), and set_zeta().
◆ history_count
|
private |
Counter for which time index we are writing to in the netcdf history file.
Definition at line 1512 of file REMORA.H.
Referenced by InitData(), WriteAtFinalTime(), WriteAtIntermediateTime(), WriteNCPlotFile(), and WriteNCPlotFile_which().
◆ istep
|
private |
which step?
Definition at line 1391 of file REMORA.H.
Referenced by advance_2d(), advance_3d(), Evolve(), EvolveOneStep(), InitData(), ReadCheckpointFile(), REMORA(), REMORA(), restart(), setup_step(), timeStep(), timeStepML(), WriteAtFinalTime(), WriteCheckpointFile(), and WritePlotFile().
◆ last_check_file_step
|
private |
Step when we last output a checkpoint file.
Definition at line 1445 of file REMORA.H.
Referenced by InitData(), restart(), WriteAtFinalTime(), and WriteAtIntermediateTime().
◆ last_check_file_time
|
private |
Simulation time when we last output a checkpoint file.
Definition at line 1447 of file REMORA.H.
Referenced by InitData(), and WriteAtIntermediateTime().
◆ last_plot_file_step
|
private |
Step when we last output a plotfile.
Definition at line 1440 of file REMORA.H.
Referenced by InitData(), WriteAtFinalTime(), and WriteAtIntermediateTime().
◆ last_plot_file_time
|
private |
Simulation time when we last output a plotfile.
Definition at line 1442 of file REMORA.H.
Referenced by InitData(), and WriteAtIntermediateTime().
◆ longwave_down_data_from_file
|
private |
Data container for downward longwave radiation flux read from file.
Definition at line 1300 of file REMORA.H.
Referenced by init_only(), and set_wind().
◆ m_bc_extdir_vals
|
private |
Array holding the Dirichlet values at walls which need them.
Definition at line 1425 of file REMORA.H.
Referenced by FillCoarsePatchMap(), init_bcs(), and init_stuff().
◆ max_step
|
private |
maximum number of steps
Definition at line 1455 of file REMORA.H.
Referenced by Evolve(), ReadParameters(), and WriteNCPlotFile_which().
◆ nc_bdry_file
|
staticprivate |
NetCDF boundary data.
Definition at line 54 of file REMORA.H.
Referenced by init_bdry_from_netcdf(), and ReadParameters().
◆ nc_clim_coeff_file
|
private |
NetCDF climatology coefficient file.
Definition at line 1612 of file REMORA.H.
Referenced by init_clim_nudg_coeff_from_netcdf(), and ReadParameters().
◆ nc_clim_his_file
|
private |
NetCDF climatology history file(s)
Definition at line 1610 of file REMORA.H.
Referenced by init_only(), and ReadParameters().
◆ nc_frc_file
|
private |
NetCDF forcing file(s)
Definition at line 1605 of file REMORA.H.
Referenced by init_only(), and ReadParameters().
◆ nc_grid_file
|
staticprivate |
NetCDF grid file.
Definition at line 56 of file REMORA.H.
Referenced by init_bathymetry_from_netcdf(), init_coriolis_from_netcdf(), init_grid_vars_from_netcdf(), init_masks_from_netcdf(), and ReadParameters().
◆ nc_grid_file_hires
|
private |
Grid file for high resolution bathymetry.
Definition at line 1590 of file REMORA.H.
Referenced by init_bathymetry_full_domain_from_netcdf(), init_grid_vars_full_domain_from_netcdf(), and ReadParameters().
◆ nc_hires_grid_box
|
private |
Box for the full domain at nc_hires_grid_level.
Definition at line 1592 of file REMORA.H.
Referenced by allocate_bathymetry_grid_vars_full_domain(), init_bathymetry_full_domain_from_netcdf(), and init_grid_vars_full_domain_from_netcdf().
◆ nc_hires_init_box
|
private |
Box for the full domain at nc_hires_init_level.
Definition at line 1599 of file REMORA.H.
Referenced by allocate_init_full_domain(), init_data_full_domain_from_netcdf(), and init_zeta_full_domain_from_netcdf().
◆ nc_init_file
|
staticprivate |
NetCDF initialization file.
Definition at line 55 of file REMORA.H.
Referenced by init_data_from_netcdf(), init_zeta_from_netcdf(), and ReadParameters().
◆ nc_init_file_hires
|
private |
Init file for high resolution.
Definition at line 1597 of file REMORA.H.
Referenced by init_data_full_domain_from_netcdf(), init_zeta_full_domain_from_netcdf(), and ReadParameters().
◆ nc_riv_file
|
private |
NetCDF river file(s)
Definition at line 1607 of file REMORA.H.
Referenced by init_only(), init_riv_pos_from_netcdf(), and ReadParameters().
◆ ncons
|
private |
Number of conserved scalars in the state (temperature + salt + passive scalars)
Definition at line 1468 of file REMORA.H.
Referenced by advance_3d(), advance_3d_ml(), allocate_init_full_domain(), foextrap_bc(), foextrap_periodic_bc(), gls_corrector(), init_bcs(), init_only(), init_scalar_metadata(), init_stuff(), InitData(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), mask_arrays_for_write(), num_bc_vars(), prestep(), ReadCheckpointFile(), ReadParameters(), RemakeLevel(), set2DPlotVariables(), set3DPlotVariables(), set_analytic_vmix(), set_hmixcoef(), set_init_data_averaged_down(), setup_step(), tke_bc(), u2d_simple_bc(), ubar_bc(), v2d_simple_bc(), vbar_bc(), WriteCheckpointFile(), WritePlotFile(), xvel_bc(), yvel_bc(), zeta_bc(), and zvel_bc().
◆ netcdf_fill_value
|
private |
fill value for masked arrays in netcdf output
Definition at line 1533 of file REMORA.H.
Referenced by ReadParameters(), and WriteNCPlotFile_which().
◆ nfast
|
private |
Number of fast steps to take.
Definition at line 1482 of file REMORA.H.
Referenced by Advance(), advance_2d(), set_weights(), and timeStepML().
◆ nscalar
|
private |
Number of passive scalars carried in the state.
Definition at line 1466 of file REMORA.H.
Referenced by init_data_from_netcdf(), init_data_full_domain_from_netcdf(), init_scalar_metadata(), and ReadParameters().
◆ nsubsteps
|
private |
How many substeps on each level?
Definition at line 1393 of file REMORA.H.
Referenced by ComputeDt(), REMORA(), REMORA(), timeStep(), and timeStepML().
◆ num_boxes_at_level
|
private |
how many boxes specified at each level by tagging criteria
Definition at line 1384 of file REMORA.H.
Referenced by init_bathymetry_from_netcdf(), init_clim_nudg_coeff_from_netcdf(), init_coriolis_from_netcdf(), init_data_from_netcdf(), init_grid_vars_from_netcdf(), init_masks_from_netcdf(), init_zeta_from_netcdf(), ReadParameters(), and refinement_criteria_setup().
◆ num_files_at_level
|
private |
how many netcdf input files specified at each level
Definition at line 1386 of file REMORA.H.
Referenced by ReadParameters().
◆ Pair_data_from_file
|
private |
Data container for air pressure read from file.
Definition at line 1296 of file REMORA.H.
Referenced by init_only(), and set_wind().
◆ phys_bc_need_data
|
private |
These are flags that indicate whether we need to read in boundary data from file.
Definition at line 1431 of file REMORA.H.
Referenced by init_bcs(), and init_bdry_from_netcdf().
◆ phys_bc_type
|
private |
Array holding the "physical" boundary condition types (e.g. "inflow")
Definition at line 1428 of file REMORA.H.
Referenced by FillBdyCCVels(), and init_bcs().
◆ physbcs
|
private |
Vector (over level) of functors to apply physical boundary conditions.
Definition at line 1405 of file REMORA.H.
Referenced by advance_3d(), FillCoarsePatchMap(), FillPatch(), gls_corrector(), init_stuff(), init_zeta_from_netcdf(), REMORA(), REMORA(), and setup_step().
◆ plot_file_name
|
private |
Plotfile prefix.
Definition at line 1492 of file REMORA.H.
Referenced by ReadParameters(), WriteNCPlotFile(), and WritePlotFile().
◆ plot_file_on_restart
|
private |
Whether to output a plotfile on restart from checkpoint.
Definition at line 1449 of file REMORA.H.
Referenced by InitData().
◆ plot_int
|
private |
Plotfile output interval in iterations.
Definition at line 1494 of file REMORA.H.
Referenced by InitData(), ReadParameters(), WriteAtFinalTime(), WriteAtIntermediateTime(), and WriteNCPlotFile_which().
◆ plot_int_time
|
private |
Plotfile output interval in seconds.
Definition at line 1496 of file REMORA.H.
Referenced by InitData(), ReadParameters(), WriteAtFinalTime(), and WriteAtIntermediateTime().
◆ plot_nodal_data
|
staticprivate |
Whether to write nodal data (Nu_nd) to plotfiles.
Definition at line 1575 of file REMORA.H.
Referenced by ReadParameters(), WriteMultiLevelPlotfileWithBathymetry(), and WritePlotFile().
◆ plot_staggered_vels
|
staticprivate |
Whether to write the staggered velocities (not averaged to cell centers)
Definition at line 1572 of file REMORA.H.
Referenced by ReadParameters(), WriteGenericPlotfileHeaderWithBathymetry(), WriteMultiLevelPlotfileWithBathymetry(), and WritePlotFile().
◆ plot_var_names_2d
|
private |
Names of 2D variables to output to AMReX plotfile.
Definition at line 1517 of file REMORA.H.
Referenced by append2DPlotVariables(), set2DPlotVariables(), and WritePlotFile().
◆ plot_var_names_3d
|
private |
Names of 3D variables to output to AMReX plotfile.
Definition at line 1515 of file REMORA.H.
Referenced by append3DPlotVariables(), set3DPlotVariables(), WriteNCPlotFile_which(), and WritePlotFile().
◆ plotfile_fill_value
|
private |
fill value for masked arrays in amrex plotfiles
Definition at line 1531 of file REMORA.H.
Referenced by ReadParameters(), and WritePlotFile().
◆ plotfile_type
|
staticprivate |
Native or NetCDF plotfile output.
Definition at line 1578 of file REMORA.H.
Referenced by ReadParameters(), and WritePlotFile().
◆ pp_prefix
| std::string REMORA::pp_prefix {"remora"} |
default prefix for input file parameters
Definition at line 291 of file REMORA.H.
Referenced by append2DPlotVariables(), append3DPlotVariables(), ReadParameters(), refinement_criteria_setup(), REMORA(), set2DPlotVariables(), and set3DPlotVariables().
◆ previousCPUTimeUsed
|
staticprivate |
Accumulator variable for CPU time used thusfar.
Definition at line 1691 of file REMORA.H.
Referenced by getCPUTime().
◆ prob
|
private |
Pointer to container of analytical functions for problem definition.
Definition at line 1381 of file REMORA.H.
Referenced by init_analytic(), init_bathymetry_full_domain_from_analytic(), init_full_domain_from_analytic(), init_full_domain_zeta_from_analytic(), REMORA(), REMORA(), set_analytic_vmix(), set_bathymetry(), set_coriolis(), set_grid_scale(), set_hmixcoef(), set_masks(), set_smflux(), set_wind(), and set_zeta().
◆ qair_data_from_file
|
private |
Data container for specific humidity read from file.
Definition at line 1294 of file REMORA.H.
Referenced by init_only(), and set_wind().
◆ rain_data_from_file
|
private |
Data container for precipitation rate read from file.
Definition at line 1302 of file REMORA.H.
Referenced by init_only(), and set_wind().
◆ ref_tags
|
staticprivate |
Holds info for dynamically generated tagging criteria.
Definition at line 1640 of file REMORA.H.
Referenced by ErrorEst(), and refinement_criteria_setup().
◆ regrid_int
|
private |
how often each level regrids the higher levels of refinement (after a level advances that many time steps)
Definition at line 1488 of file REMORA.H.
Referenced by ReadParameters(), timeStep(), and timeStepML().
◆ restart_chkfile
|
private |
If set, restart from this checkpoint file.
Definition at line 1463 of file REMORA.H.
Referenced by InitData(), MakeNewLevelFromScratch(), ReadCheckpointFile(), and ReadParameters().
◆ riv_time_varname
|
private |
Name of time field for river time.
Definition at line 1632 of file REMORA.H.
Referenced by init_only(), and ReadParameters().
◆ river_direction
|
private |
Vector over rivers of river direction: 0: u-face; 1: v-face; 2: w-face.
Definition at line 1335 of file REMORA.H.
Referenced by advance_2d(), advance_3d(), init_riv_pos_from_netcdf(), prestep_t_advection(), and rhs_t_3d().
◆ river_source_cons
|
private |
Vector of data containers for scalar data in rivers.
Definition at line 1322 of file REMORA.H.
Referenced by advance_3d(), init_only(), and prestep().
◆ river_source_transport
|
private |
Data container for momentum transport in rivers.
Definition at line 1324 of file REMORA.H.
Referenced by advance_3d(), and init_only().
◆ river_source_transportbar
|
private |
Data container for vertically integrated momentum transport in rivers.
Definition at line 1326 of file REMORA.H.
Referenced by advance_2d(), and init_only().
◆ s_r
| amrex::Gpu::DeviceVector<amrex::Real> REMORA::s_r |
Scaled vertical coordinate (range [0,1]) that transforms to z, defined at rho points (cell centers)
Definition at line 363 of file REMORA.H.
Referenced by calc_stretch_coeffs(), init_stretch_coeffs(), stretch_transform(), and WriteNCPlotFile_which().
◆ s_w
| amrex::Gpu::DeviceVector<amrex::Real> REMORA::s_w |
Scaled vertical coordinate (range [0,1]) that transforms to z, defined at w-points (cell faces)
Definition at line 365 of file REMORA.H.
Referenced by calc_stretch_coeffs(), init_stretch_coeffs(), stretch_transform(), and WriteNCPlotFile_which().
◆ salt_clim_data_from_file
|
private |
Data container for salinity climatology data read from file.
Definition at line 1319 of file REMORA.H.
Referenced by advance_3d(), and init_only().
◆ set_bcs_by_var
|
private |
whether to set boundary conditions by variable rather than just by side
Definition at line 1402 of file REMORA.H.
Referenced by init_bcs().
◆ solverChoice
|
staticprivate |
Container for algorithmic choices.
Definition at line 1525 of file REMORA.H.
Referenced by Advance(), advance_2d(), advance_3d(), bulk_fluxes(), calc_stretch_coeffs(), fill_from_bdyfiles(), FillCoarsePatchMap(), FillPatch(), gls_corrector(), init_analytic(), init_bathymetry_full_domain_from_analytic(), init_bcs(), init_beta_plane_coriolis(), init_clim_nudg_coeff(), init_clim_nudg_coeff_from_netcdf(), init_full_domain_from_analytic(), init_full_domain_zeta_from_analytic(), init_only(), init_set_vmix(), init_stuff(), init_zeta_from_netcdf(), InitData(), lin_eos(), MakeNewLevelFromScratch(), nonlin_eos(), post_timestep(), prestep(), prestep_t_advection(), prsgrd(), ReadCheckpointFile(), ReadParameters(), RemakeLevel(), rho_eos(), rhs_t_3d(), rhs_uv_2d(), rhs_uv_3d(), set2DPlotVariables(), set_analytic_vmix(), set_bathymetry(), set_coriolis(), set_grid_scale(), set_hmixcoef(), set_masks(), set_smflux(), set_wind(), set_zeta(), set_zeta_to_Ztavg(), setup_step(), stretch_transform(), t3dmix2(), timeStep(), timeStepML(), WriteCheckpointFile(), WriteNCPlotFile_which(), and WritePlotFile().
◆ srflx_data_from_file
|
private |
Data container for shortwave radiation flux read from file.
Definition at line 1298 of file REMORA.H.
Referenced by init_only(), and set_wind().
◆ start_bdy_time
|
private |
Start time in the time series of boundary data.
Definition at line 1276 of file REMORA.H.
Referenced by WriteNCPlotFile_which().
◆ start_time
|
private |
Time of the start of the simulation, in seconds.
Definition at line 1460 of file REMORA.H.
Referenced by InitData(), and ReadParameters().
◆ startCPUTime
|
staticprivate |
Variable for CPU timing.
Definition at line 1689 of file REMORA.H.
Referenced by getCPUTime(), and InitData().
◆ steps_per_history_file
|
private |
Number of time steps per netcdf history file.
-1 is the default and means code will automatically compute number of steps per file based on grid size to keep files < 2 GB
Definition at line 1510 of file REMORA.H.
Referenced by ReadParameters(), WriteNCPlotFile(), and WriteNCPlotFile_which().
◆ stop_time
|
private |
Time to stop.
Definition at line 1457 of file REMORA.H.
Referenced by ComputeDt(), Evolve(), EvolveOneStep(), and ReadParameters().
◆ sum_interval
|
staticprivate |
Diagnostic sum output interval in number of steps.
Definition at line 1564 of file REMORA.H.
Referenced by InitData(), post_timestep(), and ReadParameters().
◆ sum_per
|
staticprivate |
Diagnostic sum output interval in time.
Definition at line 1566 of file REMORA.H.
Referenced by InitData(), post_timestep(), and ReadParameters().
◆ sustr_data_from_file
|
private |
Data container for u-component surface momentum flux read from file.
Definition at line 1284 of file REMORA.H.
Referenced by init_only(), and set_smflux().
◆ svstr_data_from_file
|
private |
Data container for v-component surface momentum flux read from file.
Definition at line 1286 of file REMORA.H.
Referenced by init_only(), and set_smflux().
◆ t_new
|
private |
new time at each level
Definition at line 1395 of file REMORA.H.
Referenced by advance_2d(), ComputeDt(), Evolve(), EvolveOneStep(), FillPatch(), FillPatchNoBC(), GetDataAtTime(), gls_corrector(), init_only(), init_zeta_from_netcdf(), InitData(), MakeNewLevelFromCoarse(), ReadCheckpointFile(), RemakeLevel(), REMORA(), REMORA(), set_2darrays(), set_init_data_averaged_down(), set_zeta_averaged_down(), setup_step(), timeStep(), timeStepML(), WriteCheckpointFile(), WriteNCPlotFile_which(), and WritePlotFile().
◆ t_old
|
private |
old time at each level
Definition at line 1397 of file REMORA.H.
Referenced by advance_2d(), advance_3d(), advance_3d_ml(), FillPatch(), FillPatchNoBC(), get_t_old(), GetDataAtTime(), gls_corrector(), gls_prestep(), init_only(), init_zeta_from_netcdf(), MakeNewLevelFromCoarse(), prestep(), RemakeLevel(), REMORA(), REMORA(), set_smflux(), set_wind(), timeStep(), and timeStepML().
◆ Tair_data_from_file
|
private |
Data container for air temperature read from file.
Definition at line 1292 of file REMORA.H.
Referenced by init_only(), and set_wind().
◆ temp_clim_data_from_file
|
private |
Data container for temperature climatology data read from file.
Definition at line 1317 of file REMORA.H.
Referenced by advance_3d(), and init_only().
◆ total_nc_plot_file_step
|
static |
Definition at line 1184 of file REMORA.H.
Referenced by WriteNCPlotFile_which().
◆ u_clim_data_from_file
|
private |
Data container for u-velocity climatology data read from file.
Definition at line 1313 of file REMORA.H.
Referenced by init_only(), and setup_step().
◆ ubar_clim_data_from_file
|
private |
Data container for ubar climatology data read from file.
Definition at line 1309 of file REMORA.H.
Referenced by advance_2d(), and init_only().
◆ Uwind_data_from_file
|
private |
Data container for u-direction wind read from file.
Definition at line 1288 of file REMORA.H.
Referenced by init_only(), and set_wind().
◆ v_clim_data_from_file
|
private |
Data container for v-velocity climatology data read from file.
Definition at line 1315 of file REMORA.H.
Referenced by init_only(), and setup_step().
◆ vbar_clim_data_from_file
|
private |
Data container for vbar climatology data read from file.
Definition at line 1311 of file REMORA.H.
Referenced by advance_2d(), and init_only().
◆ vec_Akk
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Akk |
Turbulent kinetic energy vertical diffusion coefficient.
Definition at line 542 of file REMORA.H.
Referenced by advance_3d(), gls_corrector(), init_gls_vmix(), init_stuff(), ReadCheckpointFile(), resize_stuff(), and WriteCheckpointFile().
◆ vec_Akp
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Akp |
Turbulent length scale vertical diffusion coefficient.
Definition at line 544 of file REMORA.H.
Referenced by advance_3d(), gls_corrector(), init_gls_vmix(), init_stuff(), ReadCheckpointFile(), resize_stuff(), and WriteCheckpointFile().
◆ vec_Akt
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Akt |
Vertical diffusion coefficient (3D)
Definition at line 349 of file REMORA.H.
Referenced by advance_3d(), advance_3d_ml(), gls_corrector(), init_gls_vmix(), init_stuff(), prestep(), ReadCheckpointFile(), resize_stuff(), set_analytic_vmix(), and WriteCheckpointFile().
◆ vec_Akv
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Akv |
Vertical viscosity coefficient (3D)
Definition at line 347 of file REMORA.H.
Referenced by advance_3d(), advance_3d_ml(), gls_corrector(), init_gls_vmix(), init_stuff(), prestep(), ReadCheckpointFile(), resize_stuff(), set_analytic_vmix(), and WriteCheckpointFile().
◆ vec_alpha
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_alpha |
Thermal expansion coefficient (3D)
Definition at line 525 of file REMORA.H.
Referenced by init_stuff(), resize_stuff(), and setup_step().
◆ vec_beta
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_beta |
Saline contraction coefficient (3D)
Definition at line 527 of file REMORA.H.
Referenced by init_stuff(), resize_stuff(), and setup_step().
◆ vec_btflux
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_btflux |
Bottom tracer flux; input arrays.
Definition at line 417 of file REMORA.H.
Referenced by init_stuff(), resize_stuff(), and setup_step().
◆ vec_btflx
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_btflx |
Bottom tracer flux; working arrays.
Definition at line 415 of file REMORA.H.
Referenced by init_stuff(), prestep(), resize_stuff(), and setup_step().
◆ vec_bustr
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_bustr |
Bottom stress in the u direction.
Definition at line 439 of file REMORA.H.
Referenced by gls_corrector(), init_stuff(), resize_stuff(), setup_step(), and WritePlotFile().
◆ vec_bvf
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_bvf |
Brunt-Vaisala frequency (3D)
Definition at line 523 of file REMORA.H.
Referenced by gls_corrector(), init_stuff(), resize_stuff(), and setup_step().
◆ vec_bvstr
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_bvstr |
Bottom stress in the v direction.
Definition at line 441 of file REMORA.H.
Referenced by gls_corrector(), init_stuff(), resize_stuff(), setup_step(), and WritePlotFile().
◆ vec_cloud
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_cloud |
cloud cover fraction [0-1], defined at rho-points
Definition at line 424 of file REMORA.H.
Referenced by ApplyAtmosphericStates(), bulk_fluxes(), init_only(), init_stuff(), resize_stuff(), and set_wind().
◆ vec_cons_full_domain
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_cons_full_domain |
multilevel data container for high res initial data: temperature, salinity, passive tracer
Definition at line 312 of file REMORA.H.
Referenced by allocate_init_full_domain(), init_data_full_domain_from_netcdf(), init_full_domain_from_analytic(), resize_stuff(), and set_init_data_averaged_down().
◆ vec_diff2
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_diff2 |
Harmonic diffusivity for temperature / salinity.
Definition at line 355 of file REMORA.H.
Referenced by init_stuff(), mask_arrays_for_write(), resize_stuff(), set_hmixcoef(), setup_step(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_dmde
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_dmde |
d(1/m)/d(eta)
Definition at line 513 of file REMORA.H.
Referenced by advance_2d(), init_stuff(), resize_stuff(), set_curvilinear_terms_from_grid_scale(), and setup_step().
◆ vec_dndx
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_dndx |
d(1/n)/d(xi)
Definition at line 511 of file REMORA.H.
Referenced by advance_2d(), init_stuff(), resize_stuff(), set_curvilinear_terms_from_grid_scale(), and setup_step().
◆ vec_DU_avg1
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_DU_avg1 |
time average of barotropic x velocity flux (2D)
Definition at line 444 of file REMORA.H.
Referenced by advance_2d_onestep(), advance_3d_ml(), init_stuff(), ReadCheckpointFile(), resize_stuff(), WriteCheckpointFile(), and WritePlotFile().
◆ vec_DU_avg2
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_DU_avg2 |
correct time average of barotropic x velocity flux for coupling (2D)
Definition at line 446 of file REMORA.H.
Referenced by advance_2d_onestep(), advance_3d_ml(), init_stuff(), ReadCheckpointFile(), resize_stuff(), and WriteCheckpointFile().
◆ vec_DV_avg1
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_DV_avg1 |
time average of barotropic y velocity flux
Definition at line 448 of file REMORA.H.
Referenced by advance_2d_onestep(), advance_3d_ml(), init_stuff(), ReadCheckpointFile(), resize_stuff(), WriteCheckpointFile(), and WritePlotFile().
◆ vec_DV_avg2
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_DV_avg2 |
correct time average of barotropic y velocity flux for coupling (2D)
Definition at line 450 of file REMORA.H.
Referenced by advance_2d_onestep(), advance_3d_ml(), init_stuff(), ReadCheckpointFile(), resize_stuff(), and WriteCheckpointFile().
◆ vec_EminusP
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_EminusP |
evaporation minus precipitation [kg/m^2/s], defined at rho-points
Definition at line 426 of file REMORA.H.
Referenced by bulk_fluxes(), init_only(), init_stuff(), resize_stuff(), set_wind(), and set_zeta_to_Ztavg().
◆ vec_evap
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_evap |
evaporation rate [kg/m^2/s]
Definition at line 422 of file REMORA.H.
Referenced by init_stuff(), resize_stuff(), set_zeta_to_Ztavg(), setup_step(), and WriteNCPlotFile_which().
◆ vec_fcor
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_fcor |
coriolis factor (2D)
Definition at line 488 of file REMORA.H.
Referenced by advance_2d_onestep(), init_beta_plane_coriolis(), init_coriolis_from_netcdf(), init_stuff(), resize_stuff(), set_coriolis(), setup_step(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_gls
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_gls |
Turbulent generic length scale.
Definition at line 538 of file REMORA.H.
Referenced by advance_3d(), gls_corrector(), gls_prestep(), init_gls_vmix(), init_stuff(), ReadCheckpointFile(), resize_stuff(), setup_step(), and WriteCheckpointFile().
◆ vec_h
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_h |
multilevel data container for current step's z velocities (largely unused; W stored separately)
Bathymetry data (2D, positive valued, h in ROMS)
Definition at line 323 of file REMORA.H.
Referenced by advance_2d_onestep(), advance_3d_ml(), allocate_bathymetry_grid_vars_full_domain(), fill_from_bdyfiles(), init_bathymetry_from_netcdf(), init_flat_bathymetry(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), ReadCheckpointFile(), RemakeLevel(), resize_stuff(), set_bathymetry(), set_bathymetry_averaged_down(), setup_step(), stretch_transform(), WriteCheckpointFile(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_h_full_domain
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_h_full_domain |
Bathymetry data on the whole domain at each potential level.
Definition at line 326 of file REMORA.H.
Referenced by allocate_bathymetry_grid_vars_full_domain(), init_bathymetry_full_domain_from_analytic(), init_bathymetry_full_domain_from_netcdf(), init_grid_vars_full_domain_from_netcdf(), resize_stuff(), and set_bathymetry_averaged_down().
◆ vec_Huon
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Huon |
u-volume flux (3D)
Definition at line 331 of file REMORA.H.
Referenced by advance_3d_ml(), gls_corrector(), gls_prestep(), init_stuff(), prestep(), resize_stuff(), and setup_step().
◆ vec_Hvom
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Hvom |
v-volume flux (3D)
Definition at line 333 of file REMORA.H.
Referenced by advance_3d_ml(), gls_corrector(), gls_prestep(), init_stuff(), prestep(), resize_stuff(), and setup_step().
◆ vec_Hz
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Hz |
Width of cells in the vertical (z-) direction (3D, Hz in ROMS)
Definition at line 329 of file REMORA.H.
Referenced by advance_3d(), advance_3d_ml(), gls_corrector(), gls_prestep(), init_stuff(), prestep(), resize_stuff(), set_2darrays(), setup_step(), stretch_transform(), and volWgtSumMF().
◆ vec_lhflx
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_lhflx |
latent heat flux
Definition at line 406 of file REMORA.H.
Referenced by init_stuff(), resize_stuff(), setup_step(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_longwave_down
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_longwave_down |
Downward longwave radiation.
Definition at line 404 of file REMORA.H.
Referenced by ApplyAtmosphericStates(), init_only(), init_stuff(), resize_stuff(), set_wind(), and setup_step().
◆ vec_lrflx
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_lrflx |
longwave radiation
Definition at line 402 of file REMORA.H.
Referenced by init_stuff(), resize_stuff(), setup_step(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_Lscale
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Lscale |
Vertical mixing turbulent length scale.
Definition at line 540 of file REMORA.H.
Referenced by gls_corrector(), init_gls_vmix(), init_stuff(), ReadCheckpointFile(), resize_stuff(), and WriteCheckpointFile().
◆ vec_mskp
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_mskp |
land/sea mask at cell corners (2D)
Definition at line 474 of file REMORA.H.
Referenced by advance_2d_onestep(), calculate_nodal_masks(), init_masks(), init_masks_from_netcdf(), resize_stuff(), setup_step(), and update_mskp().
◆ vec_mskr
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_mskr |
land/sea mask at cell centers (2D)
Definition at line 468 of file REMORA.H.
Referenced by advance_2d_onestep(), advance_3d(), advance_3d_ml(), bulk_fluxes(), calculate_nodal_masks(), ErrorEst(), fill_3d_masks(), FillCoarsePatchMap(), FillPatch(), init_masks(), init_masks_from_netcdf(), init_zeta_from_netcdf(), MakeNewLevelFromCoarse(), mask_arrays_for_write(), ReadCheckpointFile(), RemakeLevel(), resize_stuff(), set_hmixcoef(), set_masks(), setup_step(), update_mskp(), WriteCheckpointFile(), and WritePlotFile().
◆ vec_mskr3d
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_mskr3d |
land/sea mask at cell centers, copied to all z levels (3D)
Definition at line 476 of file REMORA.H.
Referenced by ErrorEst(), fill_3d_masks(), init_masks(), and resize_stuff().
◆ vec_msku
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_msku |
land/sea mask at x-faces (2D)
Definition at line 470 of file REMORA.H.
Referenced by advance_2d_onestep(), advance_3d(), advance_3d_ml(), bulk_fluxes(), calculate_nodal_masks(), fill_from_bdyfiles(), FillCoarsePatchMap(), FillPatch(), init_masks(), init_masks_from_netcdf(), init_zeta_from_netcdf(), mask_arrays_for_write(), ReadCheckpointFile(), resize_stuff(), setup_step(), and WriteCheckpointFile().
◆ vec_mskv
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_mskv |
land/sea mask at y-faces (2D)
Definition at line 472 of file REMORA.H.
Referenced by advance_2d_onestep(), advance_3d(), advance_3d_ml(), bulk_fluxes(), calculate_nodal_masks(), fill_from_bdyfiles(), FillCoarsePatchMap(), FillPatch(), init_masks(), init_masks_from_netcdf(), init_zeta_from_netcdf(), mask_arrays_for_write(), ReadCheckpointFile(), resize_stuff(), setup_step(), and WriteCheckpointFile().
◆ vec_nudg_coeff
| amrex::Vector<amrex::Vector<std::unique_ptr<amrex::MultiFab> > > REMORA::vec_nudg_coeff |
Climatology nudging coefficients.
Definition at line 547 of file REMORA.H.
Referenced by advance_2d(), advance_3d(), fill_from_bdyfiles(), init_clim_nudg_coeff(), init_clim_nudg_coeff_from_netcdf(), init_stuff(), resize_stuff(), and setup_step().
◆ vec_Pair
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Pair |
Air pressure [mb], defined at rho-points.
Definition at line 397 of file REMORA.H.
Referenced by ApplyAtmosphericStates(), init_only(), init_stuff(), resize_stuff(), set_wind(), setup_step(), and WriteNCPlotFile_which().
◆ vec_pm
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_pm |
horizontal scaling factor: 1 / dx (2D)
Definition at line 479 of file REMORA.H.
Referenced by advance_2d_onestep(), advance_3d(), advance_3d_ml(), allocate_bathymetry_grid_vars_full_domain(), ErrorEst(), fill_from_bdyfiles(), gls_corrector(), gls_prestep(), init_grid_vars_from_netcdf(), init_stuff(), resize_stuff(), scale_rhs_vars(), scale_rhs_vars_inv(), set_curvilinear_terms_from_grid_scale(), set_grid_coords_from_grid_scale(), set_grid_scale(), set_grid_vars_averaged_down(), set_hmixcoef(), setup_step(), volWgtSumMF(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_pm_full_domain
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_pm_full_domain |
horizontal scaling factor: 1 / dx (2D) on whole domain
Definition at line 483 of file REMORA.H.
Referenced by allocate_bathymetry_grid_vars_full_domain(), init_grid_vars_full_domain_from_netcdf(), resize_stuff(), and set_grid_vars_averaged_down().
◆ vec_pn
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_pn |
horizontal scaling factor: 1 / dy (2D)
Definition at line 481 of file REMORA.H.
Referenced by advance_2d_onestep(), advance_3d(), advance_3d_ml(), allocate_bathymetry_grid_vars_full_domain(), ErrorEst(), fill_from_bdyfiles(), gls_corrector(), gls_prestep(), init_grid_vars_from_netcdf(), init_stuff(), resize_stuff(), scale_rhs_vars(), scale_rhs_vars_inv(), set_curvilinear_terms_from_grid_scale(), set_grid_coords_from_grid_scale(), set_grid_scale(), set_grid_vars_averaged_down(), set_hmixcoef(), setup_step(), volWgtSumMF(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_pn_full_domain
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_pn_full_domain |
horizontal scaling factor: 1 / dy (2D) on whole domain
Definition at line 485 of file REMORA.H.
Referenced by allocate_bathymetry_grid_vars_full_domain(), init_grid_vars_full_domain_from_netcdf(), resize_stuff(), and set_grid_vars_averaged_down().
◆ vec_qair
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_qair |
Specific humidity [kg/kg], defined at rho-points.
Definition at line 395 of file REMORA.H.
Referenced by ApplyAtmosphericStates(), init_only(), init_stuff(), resize_stuff(), set_wind(), and setup_step().
◆ vec_rain
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rain |
precipitation rate [kg/m^2/s]
Definition at line 420 of file REMORA.H.
Referenced by ApplyAtmosphericStates(), bulk_fluxes(), init_only(), init_stuff(), resize_stuff(), set_wind(), set_zeta_to_Ztavg(), and WriteNCPlotFile_which().
◆ vec_rdrag
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rdrag |
Linear drag coefficient [m/s], defined at rho points.
Definition at line 432 of file REMORA.H.
Referenced by init_stuff(), ReadCheckpointFile(), resize_stuff(), setup_step(), and WriteCheckpointFile().
◆ vec_rdrag2
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rdrag2 |
Quadratic drag coefficient [unitless], defined at rho points.
Definition at line 434 of file REMORA.H.
Referenced by init_stuff(), ReadCheckpointFile(), resize_stuff(), setup_step(), and WriteCheckpointFile().
◆ vec_rhoA
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rhoA |
vertically-averaged density
Definition at line 521 of file REMORA.H.
Referenced by advance_2d_onestep(), init_stuff(), resize_stuff(), and setup_step().
◆ vec_rhoS
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rhoS |
density perturbation
Definition at line 519 of file REMORA.H.
Referenced by Advance(), advance_2d_onestep(), init_stuff(), resize_stuff(), and setup_step().
◆ vec_river_position
|
private |
iMultiFab for river positions; contents are indices of rivers
Definition at line 1333 of file REMORA.H.
Referenced by advance_2d(), advance_3d(), init_riv_pos_from_netcdf(), init_stuff(), prestep(), and resize_stuff().
◆ vec_ru
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_ru |
u velocity RHS (3D, includes horizontal and vertical advection)
Definition at line 335 of file REMORA.H.
Referenced by advance_3d_ml(), init_only(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), ReadCheckpointFile(), RemakeLevel(), resize_stuff(), scale_rhs_vars(), scale_rhs_vars_inv(), setup_step(), and WriteCheckpointFile().
◆ vec_ru2d
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_ru2d |
u velocity RHS (2D, includes horizontal and vertical advection)
Definition at line 339 of file REMORA.H.
Referenced by advance_2d_onestep(), init_only(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), ReadCheckpointFile(), RemakeLevel(), resize_stuff(), scale_rhs_vars(), scale_rhs_vars_inv(), and WriteCheckpointFile().
◆ vec_rubar
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rubar |
barotropic x velocity for the RHS (2D)
Definition at line 452 of file REMORA.H.
Referenced by advance_2d_onestep(), init_stuff(), and resize_stuff().
◆ vec_rufrc
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rufrc |
u velocity RHS, integrated, including advection and bottom/surface stresses (2D)
Definition at line 343 of file REMORA.H.
Referenced by advance_2d_onestep(), init_stuff(), resize_stuff(), and setup_step().
◆ vec_rv
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rv |
v velocity RHS (3D, includes horizontal and vertical advection)
Definition at line 337 of file REMORA.H.
Referenced by advance_3d_ml(), init_only(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), ReadCheckpointFile(), RemakeLevel(), resize_stuff(), scale_rhs_vars(), scale_rhs_vars_inv(), setup_step(), and WriteCheckpointFile().
◆ vec_rv2d
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rv2d |
v velocity RHS (2D, includes horizontal and vertical advection)
Definition at line 341 of file REMORA.H.
Referenced by advance_2d_onestep(), init_only(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), ReadCheckpointFile(), RemakeLevel(), resize_stuff(), scale_rhs_vars(), scale_rhs_vars_inv(), and WriteCheckpointFile().
◆ vec_rvbar
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rvbar |
barotropic y velocity for the RHS (2D)
Definition at line 454 of file REMORA.H.
Referenced by advance_2d_onestep(), init_stuff(), and resize_stuff().
◆ vec_rvfrc
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rvfrc |
v velocity RHS, integrated, including advection and bottom/surface stresses (2D)
Definition at line 345 of file REMORA.H.
Referenced by advance_2d_onestep(), init_stuff(), resize_stuff(), and setup_step().
◆ vec_rzeta
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_rzeta |
free surface height for the RHS (2D)
Definition at line 456 of file REMORA.H.
Referenced by advance_2d_onestep(), init_stuff(), and resize_stuff().
◆ vec_shflx
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_shflx |
sensible heat flux
Definition at line 408 of file REMORA.H.
Referenced by init_stuff(), resize_stuff(), setup_step(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_srflx
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_srflx |
Shortwave radiation flux [W/m²], defined at rho-points.
Definition at line 400 of file REMORA.H.
Referenced by ApplyAtmosphericStates(), init_only(), init_stuff(), resize_stuff(), set_wind(), setup_step(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_sstore
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_sstore |
additional scratch space for calculations on temp, salt, etc
Definition at line 516 of file REMORA.H.
Referenced by advance_3d_ml(), init_stuff(), prestep(), resize_stuff(), and setup_step().
◆ vec_stflux
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_stflux |
Surface tracer flux; input arrays.
Definition at line 413 of file REMORA.H.
Referenced by init_stuff(), resize_stuff(), setup_step(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_stflx
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_stflx |
Surface tracer flux; working arrays.
Definition at line 411 of file REMORA.H.
Referenced by init_stuff(), prestep(), resize_stuff(), and setup_step().
◆ vec_sustr
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_sustr |
Surface stress in the u direction.
Definition at line 384 of file REMORA.H.
Referenced by gls_corrector(), init_only(), init_stuff(), resize_stuff(), set_smflux(), setup_step(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_svstr
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_svstr |
Surface stress in the v direction.
Definition at line 386 of file REMORA.H.
Referenced by gls_corrector(), init_only(), init_stuff(), resize_stuff(), set_smflux(), setup_step(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_Tair
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Tair |
Air temperature [°C], defined at rho-points.
Definition at line 393 of file REMORA.H.
Referenced by ApplyAtmosphericStates(), init_only(), init_stuff(), resize_stuff(), set_wind(), setup_step(), and WriteNCPlotFile_which().
◆ vec_tke
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_tke |
Turbulent kinetic energy.
Definition at line 536 of file REMORA.H.
Referenced by advance_3d(), gls_corrector(), gls_prestep(), init_gls_vmix(), init_stuff(), ReadCheckpointFile(), resize_stuff(), setup_step(), and WriteCheckpointFile().
◆ vec_ubar
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_ubar |
barotropic x velocity (2D)
Definition at line 458 of file REMORA.H.
Referenced by advance_2d(), advance_2d_onestep(), advance_3d_ml(), init_only(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), mask_arrays_for_write(), ReadCheckpointFile(), RemakeLevel(), resize_stuff(), set_2darrays(), timeStepML(), WriteCheckpointFile(), and WriteNCPlotFile_which().
◆ vec_uwind
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_uwind |
Wind in the u direction, defined at rho-points.
Definition at line 389 of file REMORA.H.
Referenced by ApplyAtmosphericStates(), init_only(), init_stuff(), resize_stuff(), set_wind(), and setup_step().
◆ vec_vbar
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_vbar |
barotropic y velocity (2D)
Definition at line 460 of file REMORA.H.
Referenced by advance_2d(), advance_2d_onestep(), advance_3d_ml(), init_only(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), mask_arrays_for_write(), ReadCheckpointFile(), RemakeLevel(), resize_stuff(), set_2darrays(), timeStepML(), WriteCheckpointFile(), and WriteNCPlotFile_which().
◆ vec_visc2_p
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_visc2_p |
Harmonic viscosity defined on the psi points (corners of horizontal grid cells)
Definition at line 351 of file REMORA.H.
Referenced by advance_2d_onestep(), init_stuff(), resize_stuff(), set_hmixcoef(), and setup_step().
◆ vec_visc2_r
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_visc2_r |
Harmonic viscosity defined on the rho points (centers)
Definition at line 353 of file REMORA.H.
Referenced by advance_2d_onestep(), init_stuff(), mask_arrays_for_write(), resize_stuff(), set_hmixcoef(), setup_step(), WriteNCPlotFile_which(), and WritePlotFile().
◆ vec_vwind
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_vwind |
Wind in the v direction, defined at rho-points.
Definition at line 391 of file REMORA.H.
Referenced by ApplyAtmosphericStates(), init_only(), init_stuff(), resize_stuff(), set_wind(), and setup_step().
◆ vec_weight1
| amrex::Vector<amrex::Real> REMORA::vec_weight1 |
Weights for calculating avg1 in 2D advance.
Definition at line 530 of file REMORA.H.
Referenced by advance_2d(), and set_weights().
◆ vec_weight2
| amrex::Vector<amrex::Real> REMORA::vec_weight2 |
Weights for calculating avg2 in 2D advance.
Definition at line 532 of file REMORA.H.
Referenced by advance_2d(), and set_weights().
◆ vec_xp
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_xp |
x_grid on psi-points (2D)
Definition at line 506 of file REMORA.H.
Referenced by init_grid_vars_from_netcdf(), init_stuff(), resize_stuff(), set_grid_coords_from_grid_scale(), and WriteNCPlotFile_which().
◆ vec_xr
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_xr |
x_grid on rho points (2D)
Definition at line 491 of file REMORA.H.
Referenced by init_grid_vars_from_netcdf(), init_stuff(), resize_stuff(), set_grid_coords_from_grid_scale(), and WriteNCPlotFile_which().
◆ vec_xu
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_xu |
x_grid on u-points (2D)
Definition at line 496 of file REMORA.H.
Referenced by init_grid_vars_from_netcdf(), init_stuff(), resize_stuff(), set_grid_coords_from_grid_scale(), and WriteNCPlotFile_which().
◆ vec_xv
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_xv |
x_grid on v-points (2D)
Definition at line 501 of file REMORA.H.
Referenced by init_grid_vars_from_netcdf(), init_stuff(), resize_stuff(), set_grid_coords_from_grid_scale(), and WriteNCPlotFile_which().
◆ vec_xvel_full_domain
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_xvel_full_domain |
multilevel data container for high res initial x velocities (u in ROMS)
Definition at line 314 of file REMORA.H.
Referenced by allocate_init_full_domain(), init_data_full_domain_from_netcdf(), init_full_domain_from_analytic(), resize_stuff(), and set_init_data_averaged_down().
◆ vec_yp
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_yp |
y_grid on psi-points (2D)
Definition at line 508 of file REMORA.H.
Referenced by init_grid_vars_from_netcdf(), init_stuff(), resize_stuff(), set_grid_coords_from_grid_scale(), and WriteNCPlotFile_which().
◆ vec_yr
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_yr |
y_grid on rho points (2D)
Definition at line 493 of file REMORA.H.
Referenced by init_grid_vars_from_netcdf(), init_stuff(), resize_stuff(), set_grid_coords_from_grid_scale(), and WriteNCPlotFile_which().
◆ vec_yu
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_yu |
y_grid on u-points (2D)
Definition at line 498 of file REMORA.H.
Referenced by init_grid_vars_from_netcdf(), init_stuff(), resize_stuff(), set_grid_coords_from_grid_scale(), and WriteNCPlotFile_which().
◆ vec_yv
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_yv |
y_grid on v-points (2D)
Definition at line 503 of file REMORA.H.
Referenced by init_grid_vars_from_netcdf(), init_stuff(), resize_stuff(), set_grid_coords_from_grid_scale(), and WriteNCPlotFile_which().
◆ vec_yvel_full_domain
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_yvel_full_domain |
multilevel data container for high res initial y velocities (v in ROMS)
Definition at line 316 of file REMORA.H.
Referenced by allocate_init_full_domain(), init_data_full_domain_from_netcdf(), init_full_domain_from_analytic(), resize_stuff(), and set_init_data_averaged_down().
◆ vec_z_phys_nd
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_z_phys_nd |
z coordinates at psi points (cell nodes)
Definition at line 378 of file REMORA.H.
Referenced by advance_3d_ml(), init_stuff(), MakeNewLevelFromScratch(), resize_stuff(), stretch_transform(), and WritePlotFile().
◆ vec_z_r
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_z_r |
z coordinates at rho points (cell centers)
Definition at line 358 of file REMORA.H.
Referenced by init_stuff(), resize_stuff(), setup_step(), and stretch_transform().
◆ vec_z_w
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_z_w |
z coordinates at w points (faces between z-cells)
Definition at line 361 of file REMORA.H.
Referenced by advance_3d_ml(), gls_corrector(), init_stuff(), resize_stuff(), setup_step(), and stretch_transform().
◆ vec_zeta
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_zeta |
free surface height (2D)
Definition at line 462 of file REMORA.H.
Referenced by advance_2d(), advance_2d_onestep(), allocate_init_full_domain(), fill_from_bdyfiles(), init_stuff(), init_zeta_from_netcdf(), ReadCheckpointFile(), resize_stuff(), set_zeta(), set_zeta_average(), set_zeta_averaged_down(), set_zeta_to_Ztavg(), and WriteCheckpointFile().
◆ vec_zeta_full_domain
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_zeta_full_domain |
high resolution initial free surface height (2D)
Definition at line 465 of file REMORA.H.
Referenced by allocate_init_full_domain(), init_full_domain_zeta_from_analytic(), init_zeta_full_domain_from_netcdf(), resize_stuff(), and set_zeta_averaged_down().
◆ vec_ZoBot
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_ZoBot |
Bottom roughness length [m], defined at rho points.
Definition at line 436 of file REMORA.H.
Referenced by gls_corrector(), init_stuff(), ReadCheckpointFile(), resize_stuff(), setup_step(), and WriteCheckpointFile().
◆ vec_Zt_avg1
| amrex::Vector<std::unique_ptr<amrex::MultiFab> > REMORA::vec_Zt_avg1 |
Average of the free surface, zeta (2D)
Definition at line 381 of file REMORA.H.
Referenced by advance_2d_onestep(), AverageDownTo(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), mask_arrays_for_write(), ReadCheckpointFile(), RemakeLevel(), resize_stuff(), set_zeta_average(), set_zeta_to_Ztavg(), stretch_transform(), WriteCheckpointFile(), WriteNCPlotFile_which(), and WritePlotFile().
◆ verbose
|
staticprivate |
Verbosity level of output.
Definition at line 1561 of file REMORA.H.
Referenced by estTimeStep(), Evolve(), prestep_diffusion(), ReadParameters(), sum_integrated_quantities(), and vert_visc_3d().
◆ Vwind_data_from_file
|
private |
Data container for v-direction wind read from file.
Definition at line 1290 of file REMORA.H.
Referenced by init_only(), and set_wind().
◆ write_history_file
|
staticprivate |
Whether to output NetCDF files as a single history file with several time steps.
Definition at line 1281 of file REMORA.H.
Referenced by ReadParameters(), and WriteNCPlotFile().
◆ xvel_new
| amrex::Vector<amrex::MultiFab*> REMORA::xvel_new |
multilevel data container for current step's x velocities (u in ROMS)
Definition at line 305 of file REMORA.H.
Referenced by advance_3d_ml(), allocate_init_full_domain(), AverageDownTo(), ClearLevel(), ErrorEst(), estTimeStep(), init_analytic(), init_data_from_netcdf(), init_only(), InitData(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), mask_arrays_for_write(), ReadCheckpointFile(), RemakeLevel(), REMORA(), REMORA(), set_2darrays(), set_init_data_averaged_down(), setup_step(), sum_integrated_quantities(), timeStep(), timeStepML(), WriteCheckpointFile(), WriteNCPlotFile_which(), and WritePlotFile().
◆ xvel_old
| amrex::Vector<amrex::MultiFab*> REMORA::xvel_old |
multilevel data container for last step's x velocities (u in ROMS)
Definition at line 296 of file REMORA.H.
Referenced by advance_3d(), ClearLevel(), gls_corrector(), init_only(), InitData(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), ReadCheckpointFile(), RemakeLevel(), REMORA(), REMORA(), setup_step(), timeStep(), timeStepML(), and WriteCheckpointFile().
◆ yvel_new
| amrex::Vector<amrex::MultiFab*> REMORA::yvel_new |
multilevel data container for current step's y velocities (v in ROMS)
Definition at line 307 of file REMORA.H.
Referenced by advance_3d_ml(), allocate_init_full_domain(), AverageDownTo(), ClearLevel(), ErrorEst(), estTimeStep(), init_analytic(), init_data_from_netcdf(), init_only(), InitData(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), mask_arrays_for_write(), ReadCheckpointFile(), RemakeLevel(), REMORA(), REMORA(), set_2darrays(), set_init_data_averaged_down(), setup_step(), sum_integrated_quantities(), timeStep(), timeStepML(), WriteCheckpointFile(), WriteNCPlotFile_which(), and WritePlotFile().
◆ yvel_old
| amrex::Vector<amrex::MultiFab*> REMORA::yvel_old |
multilevel data container for last step's y velocities (v in ROMS)
Definition at line 298 of file REMORA.H.
Referenced by advance_3d(), ClearLevel(), gls_corrector(), init_only(), InitData(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), ReadCheckpointFile(), RemakeLevel(), REMORA(), REMORA(), setup_step(), timeStep(), timeStepML(), and WriteCheckpointFile().
◆ zvel_new
| amrex::Vector<amrex::MultiFab*> REMORA::zvel_new |
multilevel data container for current step's z velocities (largely unused; W stored separately)
Definition at line 309 of file REMORA.H.
Referenced by advance_3d_ml(), AverageDownTo(), ClearLevel(), ErrorEst(), estTimeStep(), init_only(), InitData(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), ReadCheckpointFile(), RemakeLevel(), REMORA(), REMORA(), setup_step(), timeStep(), timeStepML(), WriteCheckpointFile(), and WritePlotFile().
◆ zvel_old
| amrex::Vector<amrex::MultiFab*> REMORA::zvel_old |
multilevel data container for last step's z velocities (largely unused; W stored separately)
Definition at line 300 of file REMORA.H.
Referenced by ClearLevel(), init_only(), InitData(), MakeNewLevelFromCoarse(), MakeNewLevelFromScratch(), ReadCheckpointFile(), RemakeLevel(), REMORA(), REMORA(), setup_step(), timeStep(), timeStepML(), and WriteCheckpointFile().
The documentation for this class was generated from the following files:
- /home/runner/work/REMORA/REMORA/Source/REMORA.H
- /home/runner/work/REMORA/REMORA/Source/BoundaryConditions/REMORA_BoundaryConditions_netcdf.cpp
- /home/runner/work/REMORA/REMORA/Source/BoundaryConditions/REMORA_FillPatch.cpp
- /home/runner/work/REMORA/REMORA/Source/Initialization/REMORA_init.cpp
- /home/runner/work/REMORA/REMORA/Source/Initialization/REMORA_init_bcs.cpp
- /home/runner/work/REMORA/REMORA/Source/Initialization/REMORA_init_from_netcdf.cpp
- /home/runner/work/REMORA/REMORA/Source/Initialization/REMORA_make_new_level.cpp
- /home/runner/work/REMORA/REMORA/Source/IO/REMORA_Checkpoint.cpp
- /home/runner/work/REMORA/REMORA/Source/IO/REMORA_console_io.cpp
- /home/runner/work/REMORA/REMORA/Source/IO/REMORA_NCPlotFile.cpp
- /home/runner/work/REMORA/REMORA/Source/IO/REMORA_Plotfile.cpp
- /home/runner/work/REMORA/REMORA/Source/IO/REMORA_SetPlotVars.cpp
- /home/runner/work/REMORA/REMORA/Source/IO/REMORA_writeJobInfo.cpp
- /home/runner/work/REMORA/REMORA/Source/REMORA.cpp
- /home/runner/work/REMORA/REMORA/Source/REMORA_Coupling.cpp
- /home/runner/work/REMORA/REMORA/Source/REMORA_SumIQ.cpp
- /home/runner/work/REMORA/REMORA/Source/REMORA_Tagging.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_Advance.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_advance_2d.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_advance_2d_onestep.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_advance_3d.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_advance_3d_ml.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_apply_clim_nudg.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_bulk_flux.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_ComputeTimestep.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_coriolis.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_curvilinear.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_gls.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_prestep.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_prestep_diffusion.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_prestep_t_advection.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_prsgrd.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_rho_eos.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_rhs_t_3d.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_rhs_uv_2d.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_rhs_uv_3d.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_scale_rhs_vars.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_set_weights.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_setup_step.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_t3dmix.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_TimeStep.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_TimeStepML.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_update_massflux_3d.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_uv3dmix.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_vert_mean_3d.cpp
- /home/runner/work/REMORA/REMORA/Source/TimeIntegration/REMORA_vert_visc_3d.cpp
- /home/runner/work/REMORA/REMORA/Source/Utils/REMORA_DepthStretchTransform.H